机构名称:
¥ 2.0
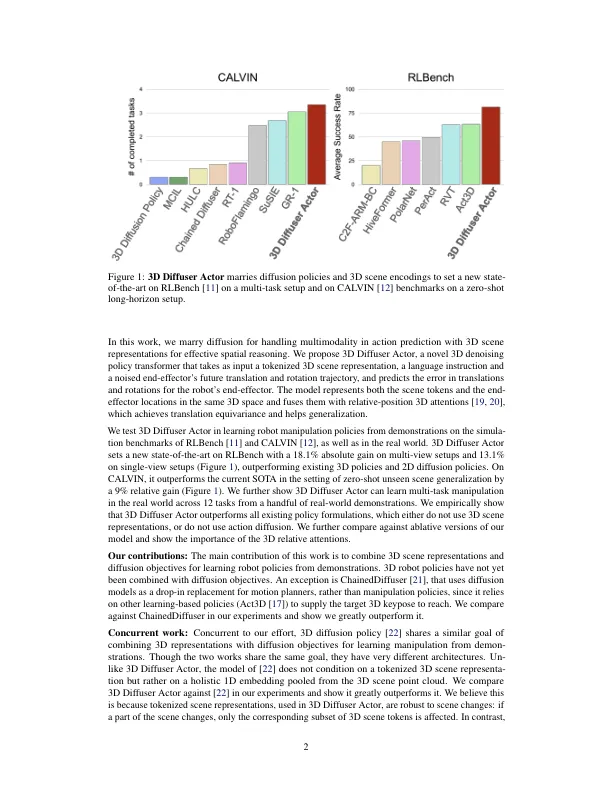
摘要:扩散策略是有条件的扩散模型,这些模型学习以机器人和环境状态为条件的机器人动作分布。他们最近显示出胜过确定性和替代作用分布学习公式的表现。3D机器人策略使用3D场景特征表示形式使用感应深度从单个或多个相机视图汇总。他们已经显示出比在相机观点之间更好地概括其2D对应物。我们统一了这两条工作和现在的3D扩散器演员,这是一种具有新颖的3D DeNoising Transformer的神经政策,它融合了来自3D视觉场景的信息,语言指令和本体感受,以预测NOISISE 3D ROBOT姿势的噪声。3D扩散器Actor在RLBench上设置了新的最先进的,其绝对性能增益比当前的SOTA在多视图设置上占据了18.1%,并且在单视图设置上的绝对增益为13.1%。在加尔文基准测试上,它比当前的SOTA相对增加了9%。它还学会了通过少数示威来控制现实世界中的机器人操纵器。通过与当前的SOTA策略和模型的消融进行彻底比较,我们显示了3D扩散器演员的设计选择极大地超过了2D表示,回归和分类目标,绝对关注和整体非言语的非言语非言语的3D场景嵌入。
与3D场景表示形式的策略扩散
主要关键词




相关文件推荐