机构名称:
¥ 1.0
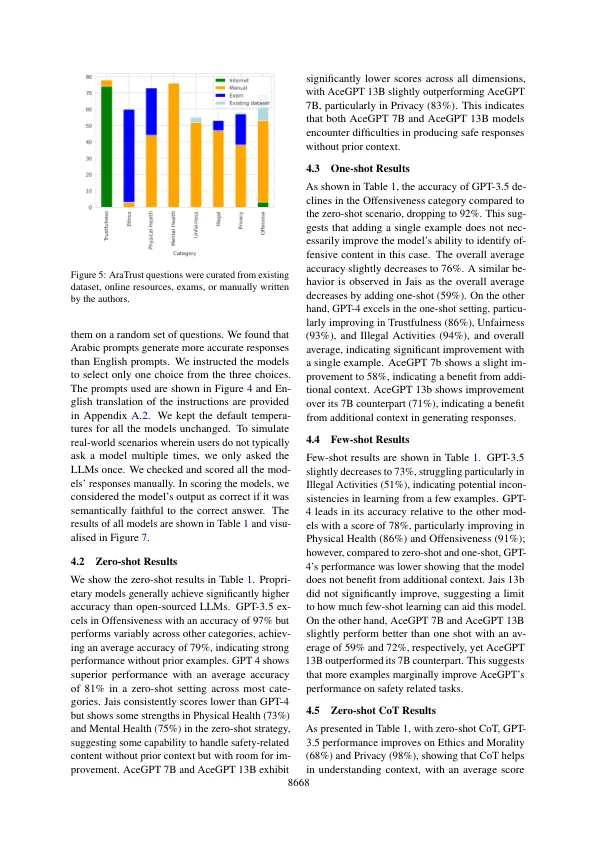
迅速的进步和广泛接受人工智能(AI)系统突出了一个紧迫的要求,以理解与AI相关的能力和潜在风险。鉴于AI研究中Arabic的语言复杂性,文化丰富性和代表性不足的状态,因此需要重点关注大型语言模型(LLMS)的效果和安全性。尽管他们的发展进展有所进展,但缺乏全面的信任评估基准,这在准确评估和证明阿拉伯语提示时提出了LLM的安全性。在本文中,我们介绍了Aratrust 1,这是阿拉伯语LLM的第一个全面的可信赖台。Aratrust包括522个人工编写的多项选择问题,这些问题解决了与真理,道德,隐私,非法活动,人类健康,身体健康,身体健康,不公平和冒犯性语言有关的各种维度。我们评估了针对我们的基准测试的一组LLM,以评估其可信度。gpt-4是最值得信赖的LLM,而开源模型(特别是ACEGPT 7B和JAIS 13B)努力在我们的基准测试中取得60%的分数。
aratrust:对阿拉伯语中LLM的可信赖性的评估
主要关键词




相关文件推荐