机构名称:
¥ 1.0
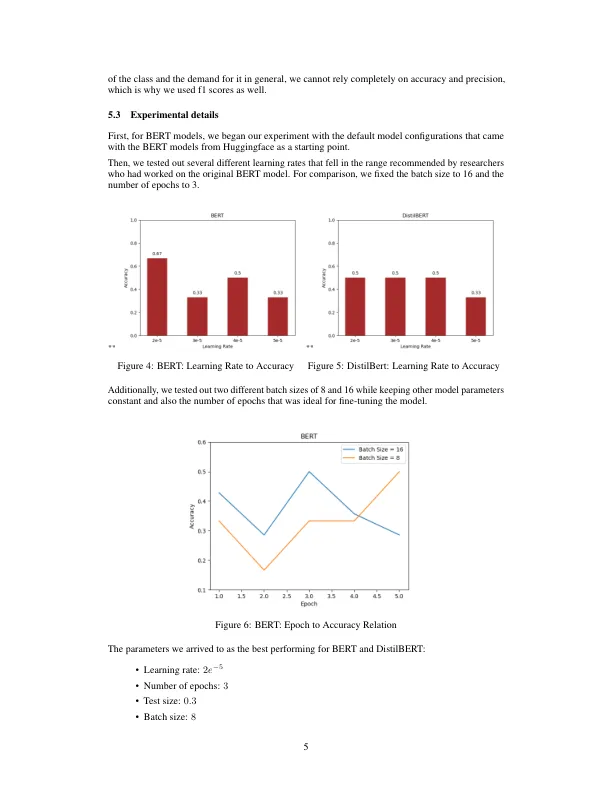
首先,鉴于BERT与Flan-T5相比在课程和季度分类方面表现更好,我们可以推测为什么可能是这样。鉴于Bert和Flan-T5都使用双向上下文建模(考虑到前面的单词和成功的单词),因此这两个模型似乎不太可能对评论的语义进行不同的处理。However, there is a significant difference between the two in that while the BERT model directly outputs a prediction based on the tokenized review as input, the FLAN-T5 model does have to go through an additional preprocessing step of attaching a prefix to each review, instructing the model to output a certain type of output (e.g.请'输出一个在0到208之间的数字,对于209个标签课程分类),这意味着,对于Flan-T5输入的每个评论实际上在前缀上延长了较长的时间,并且可能在隔离和评估评论本身时会给模型带来更多的混淆空间。
Stanford CS课程 +基于CARTA评论的四分之一分类
主要关键词




相关文件推荐