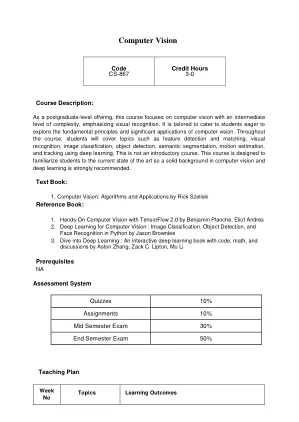
机构名称:
¥ 1.0
图1。想象我们在多视图输入图像上使用了2D视觉操作员,例如语义分割或场景编辑。这通常会导致不同视图的预测不一致(如中间列所示)。为了解决这个问题,我们介绍了Lift3D,这是一个框架,旨在将这些不一致的2D输出转换为视图一致的3D预测(在右列中说明)。我们的方法既是场景又是操作员 - 不可思议的,这意味着它可以适应任何下游任务或场景,而无需其他调整。我们演示了Lift3D如何有效地解决开放词汇细分和文本驱动场景编辑的多视图预测中的矛盾。请注意,在底部行的2D结果中,在相同最右边的椅子上的颜色差异(从红色到绿色),面部和头发颜色的不一致。为了在2D和3D结果之间进行更清晰的比较,我们建议缩放此图像的电子版本。
计算机视觉简介I CSE 152A讲座1
主要关键词





相关文件推荐