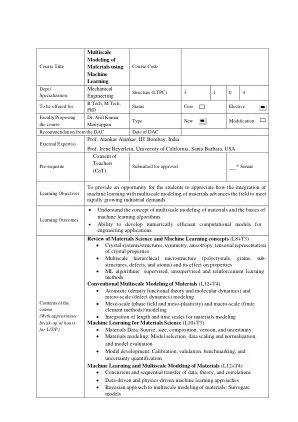
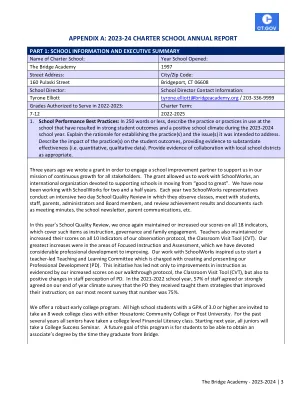
机构名称:
¥ 13.0
回归是预测连续价值的过程。我们可以使用回归方法来预测使用其他一些变量的连续值,例如CAR模型的CO2发射。例如,让我们假设我们可以访问包含与来自不同汽车的CO2排放相关的数据的数据集。数据集包含诸如汽车发动机尺寸,气缸数,燃油消耗量和来自各种汽车型号的CO2排放之类的属性。现在,我们有兴趣估计其生产后新车模型的近似CO2发射。使用机器学习回归模型这是可能的。在回归中,有两种类型的变量:一个因变量和一个或多个自变量。因变量是我们研究和尝试预测的“状态”,“目标”或“最终目标”,而自变量(也称为解释变量)是这些“状态”的“原因”。自变量通常通过x显示,并且因变量用y表示。回归模型将y或因变量与x的函数相关联,即自变量。回归的关键点是因变量值应该是连续的,而不是离散值。但是,可以在分类或连续测量量表上测量自变量或变量。回归的类型:基本上,回归模型有两种类型:简单回归和多重回归。简单回归是当使用一个自变量来估计因变量时。它可以在非线性上是线性的。例如,使用“汽车的发动机尺寸”预测CO2排放。回归的线性基于自变量和因变量之间关系的性质。存在多个自变量时,该过程称为多个线性回归。例如,使用变量“汽车的发动机尺寸”和“汽车中存在的气缸数”来预测CO2排放。再次取决于因变量和自变量之间的关系,多个线性回归可以是线性或非线性回归。
(2020-24批次):机器学习 - 单元1材料
主要关键词





相关文件推荐