
机构名称:
¥ 1.0
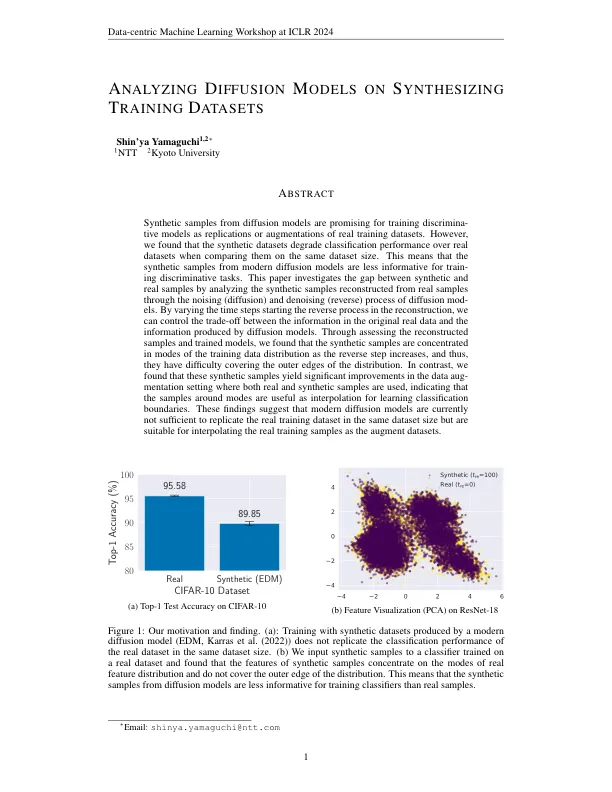
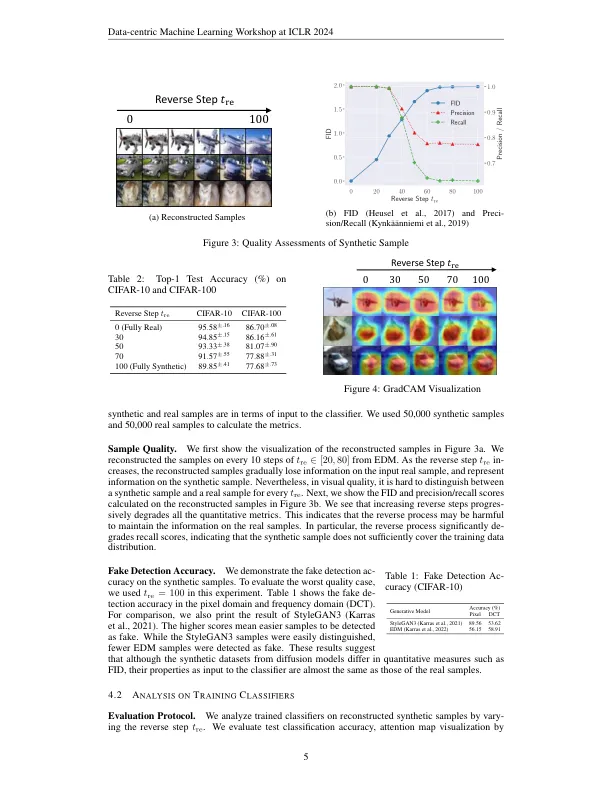
从扩散模型中的合成样本对于训练歧视模型作为重复或增强真实培训数据集有希望。但是,我们发现合成数据集在同一数据集大小上比较它们时,合成数据集降低了分类性能。这意味着现代扩散模型的合成样本对于训练歧视任务的信息较少。本文通过分析从实际样品(扩散)(扩散)和脱氧(反向)扩散模型过程中从真实样品重建的合成样品来研究合成和真实样品之间的差距。通过改变重建的时间步骤开始反向过程的时间步骤,我们可以控制原始真实数据中的信息与扩散模型产生的信息之间的权衡。通过评估重建的样品和训练有素的模型,我们发现合成样品集中在训练数据分布的模式中,随着反向步骤的增加,它们很难覆盖分布的外边缘。相反,我们发现这些合成样本在使用真实和合成样品的数据设置中产生了显着改善,这表明模式周围的样品可作为学习分类边界的插值有用。这些发现表明,现代扩散模型目前不足以复制相同数据集大小的真实培训数据集,但适合将真实培训样本作为增强数据集进行插值。
分析有关合成的扩散模型...
主要关键词



相关文件推荐





























