
机构名称:
¥ 3.0
学分:[1] Christiano等。,《神经》 17中的深入强化从人类的偏好中学习。[2] Ziegler等。,来自人类偏好的微调语言模型,在Arxiv'19中。[3] Ouyang等。,培训语言模型在Neurips'22中按照人为反馈的指示进行指示。[4] Rafailov等。,直接偏好优化:您的语言模型是秘密的奖励模型,在Neurips'23中。[5] Hong等。,ORPO:Arxiv'24中的无参考模型的单片偏好优化。
通过加强学习的偏好对齐...
主要关键词


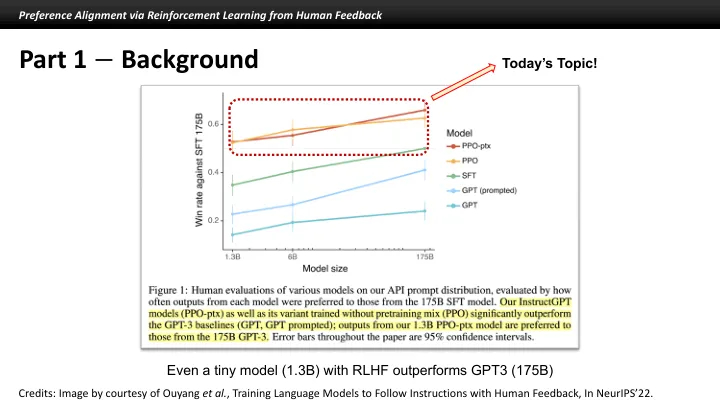
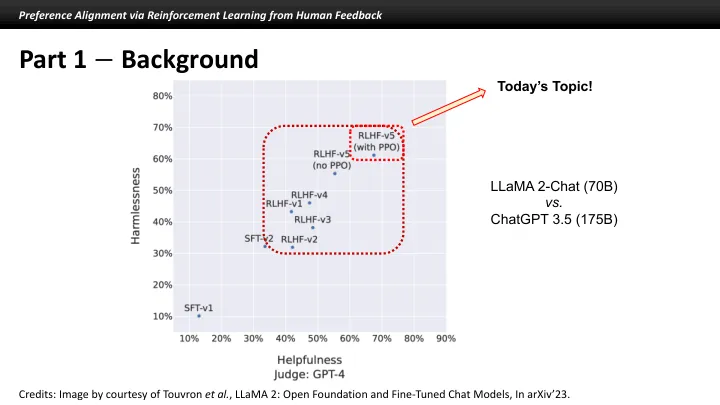

相关文件推荐





























