XiaoMi-AI文件搜索系统
World File Search System扩散模型

扩散模型 - 主论文
我们的发现表明,在向后过程中,在向后过程中选择特征信息的破坏主要取决于噪声方差时间表。值得注意的是,在线性时间表下,扩散链可以分为不同的区域。以高信息保留为特征的初始阶段主要有助于样本美学而没有改变基本特征。以对称为中心的后续区域以扩散过程为中心,是特征选择的关键关头。令人惊讶的是,我们观察到这些选择不是瞬时的,而是在几个降解步骤中发展的。这种认识在解决我们的研究问题方面具有重要意义。另一个地区的第三个区域不那么有趣。样本一旦到达这些信息就会丢失所有信息,并且它们本质上过渡到该地区的正常样本。

通过双层引导扩散模型
可以通过最大似然eS-定时(MLE)定义为X ML = Arg Max Max X Log P(Y | X)的最大似然性(MLE)的解决方案y = a x + n,可以概率地得出。尽管如此,如果向前操作员A是单数的,例如,当M 在这种情况下,仅使用观察到的测量y仅使用观察到的y,即使在y = y = ax的无噪声场景中,也只能使用观察到的测量y唯一地恢复信号集x是不可行的。 由于a的空空间的非平凡性,因此出现了这一挑战。 为了减轻适应性,必须基于先验知识来限制可能解决方案的空间,因此必须合并一个额外的假设。 主要采用的框架提供了更有意义的解决方案是最大的后验(MAP)估计,该估计为x Map = arg max = arg max x [log p(y | x) + log p(x)],其中术语log p(x)封装了清洁图像x的先前信息。 随着时间的流逝,解决反问题的先验概念已经大大发展。 从经典上讲,许多方法论依赖于手工制作的先验,这些方法是分析定义的约束,例如稀疏性[10,31],低率[14,16],总变化[9],但要命名为少数,以增强重建。 随着深度学习模型的出现,先验已过渡到数据驱动,从而在重建质量方面产生了很大的提高[1,2,7,7,17,34]。 无监督的学习范式中的策略因学识渊博的先验方式而异(又称在这种情况下,仅使用观察到的测量y仅使用观察到的y,即使在y = y = ax的无噪声场景中,也只能使用观察到的测量y唯一地恢复信号集x是不可行的。由于a的空空间的非平凡性,因此出现了这一挑战。为了减轻适应性,必须基于先验知识来限制可能解决方案的空间,因此必须合并一个额外的假设。主要采用的框架提供了更有意义的解决方案是最大的后验(MAP)估计,该估计为x Map = arg max = arg max x [log p(y | x) + log p(x)],其中术语log p(x)封装了清洁图像x的先前信息。随着时间的流逝,解决反问题的先验概念已经大大发展。从经典上讲,许多方法论依赖于手工制作的先验,这些方法是分析定义的约束,例如稀疏性[10,31],低率[14,16],总变化[9],但要命名为少数,以增强重建。随着深度学习模型的出现,先验已过渡到数据驱动,从而在重建质量方面产生了很大的提高[1,2,7,7,17,34]。无监督的学习范式中的策略因学识渊博的先验方式而异(又称这些先验,无论是以受监督的或无监督的方式学习的,都已集成到地图框架中,以解决不适合的反问题。在监督范式中,对配对的原始图像的可用性和观察到的测量值的依赖也可能限制模型的通用性。结果,这种趋势已转向对无监督的兴趣的日益兴趣,在这种情况下,使用深层生成模型隐式或明确地学习了先生。
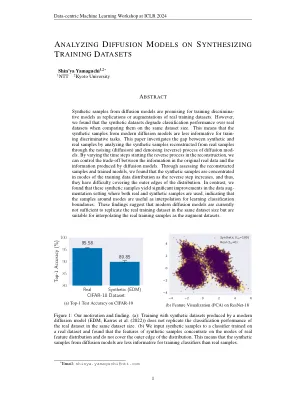
分析有关合成的扩散模型...
从扩散模型中的合成样本对于训练歧视模型作为重复或增强真实培训数据集有希望。但是,我们发现合成数据集在同一数据集大小上比较它们时,合成数据集降低了分类性能。这意味着现代扩散模型的合成样本对于训练歧视任务的信息较少。本文通过分析从实际样品(扩散)(扩散)和脱氧(反向)扩散模型过程中从真实样品重建的合成样品来研究合成和真实样品之间的差距。通过改变重建的时间步骤开始反向过程的时间步骤,我们可以控制原始真实数据中的信息与扩散模型产生的信息之间的权衡。通过评估重建的样品和训练有素的模型,我们发现合成样品集中在训练数据分布的模式中,随着反向步骤的增加,它们很难覆盖分布的外边缘。相反,我们发现这些合成样本在使用真实和合成样品的数据设置中产生了显着改善,这表明模式周围的样品可作为学习分类边界的插值有用。这些发现表明,现代扩散模型目前不足以复制相同数据集大小的真实培训数据集,但适合将真实培训样本作为增强数据集进行插值。

有条件扩散模型作为自我
不规则的时间序列在医疗保健中无处不在,应用程序从预测患者的健康状况到归咎于缺失值的应用。条件扩散模型中的最新开发方法,这些模型基于观察到的数据预测缺失值,对定期定期时间序列的构成有很大的希望。它还通过用注入可变量表的噪声替换部分掩盖的局部掩盖来概括了掩盖重建的自我监督学习任务,并显示了图像识别的竞争结果。尽管对扩散模型的兴趣日益增强,但它们对不规则时间序列数据的潜力,尤其是在下游任务中,仍然没有被逐渐置换。我们提出了一个有条件的扩散模型,该模型设计为一种自我监督的学习骨干,用于此类数据,集成了可学习的时间嵌入以及一种跨维度注意机制,以解决数据的复杂时间动态。该模型不仅适合有条件的生成任务,而且还获得了隐藏的状态,对歧视任务有益。经验证据证明了我们的模型在插补和分类任务中的优势。

讲座4 - 扩散模型简介
歌曲和Ermon指出,现有模型具有重大局限性:“基于可能性的模型要么需要对模型架构进行强限制,以确保可拖动的归一化常规常量以进行可能性计算,要么必须依靠代孕目标来近似最大的可能性训练。隐性生成模型通常需要对抗训练,众所周知,这是不稳定的,可能导致模式崩溃”。归一化常规,不稳定性和模式崩溃已经是显式密度文献采样多年来所处理的主要计算问题。在这里,我们介绍了另一种表示概率分布的方式

EDM2+:探索有效的扩散模型...
扩散模型的训练和采样已在先前的艺术中详尽阐明(Karras等,2022; 2024b)。取而代之的是,底层网络架构设计保持在摇摇欲坠的经验基础上。此外,根据最新规模定律的趋势,大规模模型涉足生成视觉任务。但是,运行如此大的扩散模型会造成巨大的综合负担,从而使其具有优化的计算并有效分配资源。为了弥合这些空白,我们浏览了基于u-NET的效率扩散模型的设计景观,这是由声望的EDM2引起的。我们的勘探路线沿两个关键轴组织,层放置和模块插入。我们系统地研究基本设计选择,并发现了一些有趣的见解,以提高功效和效率。这些发现在我们的重新设计的架构EDM2+中,这些发现将基线EDM2的计算复杂性降低了2倍,而不会损害生成质量。广泛的实验和比较分析突出了我们提出的网络体系结构的有效性,该结构在Hallmark Imagenet基准上实现了最先进的FID。代码将在接受后发布。

通过随机差异基于得分的扩散模型...
和连续扩散模型,因为SDE指定的扩散模型可以视为离散模型的连续限制(第3节),并且通过合适的时间离散化从连续模型中获得离散扩散模型(第5.3节)。观点是SDES揭示了模型的结构属性,而离散的对应物是实际的实现。本文的目的是为基于分数的扩散模型的最新理论提供教程,主要是从统计重点的连续角度来看。也将提供离散模型的参考。我们为大多数已陈述的结果绘制证明,并且仅在分析至关重要时才给出假设。我们经常使用“在适当条件”的“在适当条件下”的短语,以避免不太重要的技术细节,并保持简洁和关注点。该论文是对该领域的温和介绍,从业者将发现一些分析对于设计新模型或算法有用。在这里首次出现一些结果(例如,在第5.2、6.2和7.3节中)。由于采用了SDE公式,因此我们假设读者熟悉基本的随机演算。ØKksendal的书[50]提供了一个用户友好的帐户,以进行随机分析,并且更高级的教科书是[34,68]。另请参见[76]有关扩散模型的文献综述,以及[8]进行优化概述,并具有更高级的材料,例如扩散指导和微调。本文的其余部分如下组织。具体示例在第3节中提供了。在第2节中,我们从扩散过程的时间反转公式开始,这是扩散模型的基石。第4节与分数匹配技术有关,这是扩散模型的另一种关键要素。在第5节中,我们考虑扩散模型的随机采样器,并分析其收敛性。在第6节中,确定性采样器 - 引入了概率流,以及其应用于一致性模型。在第7节中给出了分数匹配的其他结果。总结说明和未来的指示在第8节中总结了。

具有确定性指导扩散模型
摘要。天气预报需要立即决策的确定性结果,也需要评估不可能的概率结果。但是,确定性模型可能无法完全捕获天气可能性的规范,概率预测可能缺乏特定计划所需的精确度,因为该领域旨在提高准确性和可靠性,因此面临重大挑战。在本文中,我们提出了基于确定性指导的扩散模型(DGDM),以利用确定性和概率天气前铸造模型的好处。DGDM集成了确定性分支和扩散模型作为概率分支,以提高预测精度,同时提供概率预测。此外,我们还引入了序列方差时间表,该序列方差时间表从不久的将来到遥远的未来进行了预测。此外,我们通过使用确定性分支的结果来提出截断的扩散,以截断差异模型的反向过程以控制不确定性。我们在移动MNIST上对DGDM进行了广泛的分析。此外,我们评估了Pacific Northwest风暴(PNW)typhoon卫星数据集的DGDM的有效性,用于区域极端天气预测,以及在WeatherBench数据集上用于全球天气预测数据集。实验结果表明,DGDM不仅在全球预测中,而且在区域预测方案中都能达到最先进的绩效。该代码可在以下网址提供:https://github.com/donggeun-yoon/dgdm。


3D人类运动扩散模型
工作描述人类运动生成是计算机图形的关键任务,对于涉及虚拟字符(例如电影制作或虚拟现实体验)的应用至关重要。最近的深度学习方法,尤其是生成模型,开始在该领域做出重大贡献。虽然早期的神经方法着重于生动和现实的人类运动序列的无条件产生,但最新的方法指导使用各种条件信号(包括动作类别,文本和音频)的运动产生。中,基于扩散的模型已显示出巨大的成功,主要是研究前沿[TRG * 23,KKC23,ZCP ∗ 24,DMGT23]。