XiaoMi-AI文件搜索系统
World File Search SystemExome

演讲嘉宾
DAVID SPETZLER,理学硕士、博士、工商管理硕士 Caris Life Sciences 总裁 亚利桑那州凤凰城 Spetzler 博士目前领导 Caris Life Sciences 的临床运营、研发、信息技术、生物信息学和生物制药服务。作为分子科学和精准医学的创新者,Spetzler 博士坚持不懈地致力于改善患者护理。他领导了公司每项临床产品的开发,包括 2019 年推出临床全转录组测序和 2020 年推出全外显子组测序。最近,他领导推出了 Caris 首款基于人工智能的临床产品 Caris GPSai™ 和 FOLFIRSTai™。他还领导了 Caris Assure™ 的最新开发和推出,这是一种新的全外显子组和全转录组液体活检检测方法,可对血浆和白膜中的 DNA 和 RNA 进行测序,从而无需组织标本即可为患者提供灵敏的检测。 Spetzler 博士负责监督公司独家技术 ADAPT 的开发,该技术能够测量数千种蛋白质畸变,并用于开发早期癌症检测检测、发现新型药物靶点和描述每位患者肿瘤中的蛋白质差异。他还领导公司专有 AI 平台 (DEAN) 的持续开发,以创建和验证数十种机器学习签名,称为 Next Generation Profiling™ (NGP),从而使用当今癌症患者可用的最全面的临床产品套件提供最深入和独特的分析和解释。在亚利桑那州立大学,Spetzler 博士获得了数学和统计科学学院计算生物科学硕士学位、分子和细胞生物学博士学位和工商管理硕士学位。Spetzler 博士是亚利桑那州立大学分子细胞生物学项目的兼职教员,也是 NSF 的 SBIR/STTR 拨款的科学和商业审查员。

Illumina DNA准备化学
除了提供快速工作流程外,Illumina DNA准备化学为输入类型和输入量提供了非凡的灵活性,包括直接的新鲜血液或唾液的直接样品输入,并支持广泛的应用(表1)。Illumina DNA Prep与全基因组测序(WGS)应用兼容,包括人,小/微生物和大型复杂基因组测序。对于有针对性的DNA富集应用,包括不同尺寸的固定和自定义面板以及全外显子组测序(WES),Illumina提供具有富集的Illumina DNA Prep,其具有丰富的珠子连接的转座体(EBLTS),以提供丰富的兼容库兼容库。此外,具有富集的Illumina DNA准备与Illumina和第三方富集探针/面板兼容,从而使内容可移植性提高了灵活性。

低分化高
为罹患极为罕见、高度侵袭性肿瘤(如高级别神经内分泌宫颈癌 (NETc))的患者寻找新的有效治疗方式仍然是一项尚未得到满足的医疗需求。通过对大量 NETc 患者进行综合全外显子组和 RNA 测序分析,我们确定了反复突变的基因和改变的细胞内信号传导细胞通路,为靶向治疗提供了应用。使用两个完全测序的患者来源的异种移植瘤(ERBB2/PIK3CA/AKT 通路发生改变),我们发现 copanlisib (PIK3CAi)、阿法替尼 (pan - HERi) 和 elimusertib (ATRi) 单药治疗以及 copanlisib/阿法替尼和 copanlisib/elimusertib 的组合可显著抑制 NETc PDX 生长。我们的综合基因分析结合体内临床前验证实验表明,大量高级别 NETc 可能从靶向药物的重新利用中受益。

新型候选基因MACF1与伊朗家族中的常染色体显性非综合性听力损失有关
案例报告社会福利与康复科学大学遗传学诊所的证据。概率具有HL的广泛家族史(图1),伴随着没有其他表型表现。获得知情同意后,从参与成员中收集全血样本,并提取基因组DNA(图1)。受影响的家庭成员接受了临床重新评估,以排除潜在的HL综合症综合症形式。对受影响的个体进行了纯音调测定法,并显示出轻度的倾斜到严重的HL。HL被描述为语言和进步。个体III.3在低频中显示出更严重的HL,并且可能随着年龄的增长而代表低频的某些进展。最初,概率进行了GJB2测试,该测试没有发现因果突变。随后,概率进行了外部测序(ES)以确定遗传原因


人工智能可全面解读基因组并确定罕见遗传病的候选诊断
方法 我们对 119 名被诊断患有罕见遗传病、在雷迪儿童医院接受全基因组测序 (WGS) 的先证者(其中大部分是 NICU 婴儿)的回顾性队列中的 GEM 进行了基准测试。我们还对在另外五家学术医疗中心确诊的 60 例病例的另一队列进行了复制研究。为了进行比较,我们还使用常用的变异优先级工具(Phevor、Exomiser 和 VAAST)分析了这些病例。比较包括三重奏、二重奏和单例的 WGS 和全外显子组测序 (WES)。诊断所依据的变异涵盖了多种遗传方式和类型,包括结构变异 (SV)。患者表型是手动或通过自动临床自然语言处理 (CNLP) 从临床记录中提取的。最后,重新分析了 14 个以前未解决的案件。

阿拉文德医学研究基金会
莱伯氏先天性黑蒙 (LCA) 是一种早期严重的遗传性视网膜营养不良症,占所有遗传性视网膜病变的 5%。每 30,000 到 81,000 个活产婴儿中就有 1 个患有此病。在全球范围内,29 种基因与 LCA 发病机制有关,占确诊病例的 70%。尽管 LCA 罕见,但我们最近五年的前瞻性调查诊断出了 135 例 LCA 病例,表明由于近亲结婚和族内通婚的普遍做法,南印度人群的患病率更高。使用靶向基因组对 135 例 LCA 病例进行分子诊断,确定了 21 个已知 LCA 候选基因的突变,检出率为 84%。然而,16% 的基因未解决的病例将进一步进行全面的表型分析结合全外显子组测序,以解码与 LCA 相关的潜在遗传因素。

标题:肠道菌群脑瘤诱导的肠道菌群失调调节1
体细胞变体检测是癌症基因组学分析的组成部分。尽管大多数方法都集中在短阅读测序上,但长阅读技术现在在重复映射和变体相位方面具有潜在的优势。我们提出了一种深度学习方法,一种深度学习方法,用于从短读和长阅读数据中检测体细胞SNV,插入和缺失(indels),具有用于全基因组和外显子组测序的模式,并且能够以肿瘤正常,唯一的肿瘤正常,ffpe pppe的样本进行运行。为了帮助解决公共可用培训的缺乏和基准测试数据以进行体细胞变体检测,我们生成并公开提供了一个与Illumina,Pacbio Hifi和Oxford Nanopore Technologies的五个匹配的肿瘤正常细胞线对的数据集,以及基准的变体。在样本和技术(短读和长阅读)中,深度态度始终优于现有呼叫者,特别是对于Indels而言。

运动障碍的基因检测:临床实用程序的综述
诊断产量最简单,最量化的诊断效用指标是诊断产量,使用特定的基因测试方法为给定队列建立的遗传诊断比例。诊断产量取决于多个因素,包括但不限于目标人群的特征(例如,运动障碍的类型,家族病史的存在/不存在,症状发作的年龄,种族背景年龄),使用的遗传测试类型,使用的遗传测试类型(例如,使用Sanger测序,短读NGS,长期阅读序列,长期序列,重复验证,或使用Soutlern-Report-Report-Artim-Repret-Aprip和//或/或/或使用Soutlern blimers和////或PCR]),测序靶(例如,单基因,靶向基因面板,整个外显子组测序[WES]还是整个基因组测序[WGS]),无论单胎,三重奏和/或家庭数据是否可用于分析,生物学分析的类型和范围,生物信息分析的类型和程度,以及严格标准化的变异策划标准的严格标准化型培养标准的分类,适用于Variants [8]。
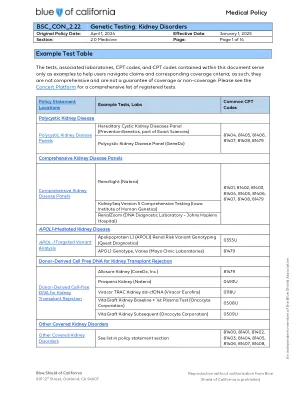
bsc_con_2.22基因测试:肾脏疾病
描述间接影响肾脏的遗传性肾脏疾病和遗传性疾病可能很常见,例如常染色体显性型多囊性肾脏疾病或罕见,例如Lowe综合征和Fabry病。确定遗传性肾脏疾病的遗传原因可以帮助指导治疗,告知家庭成员,并为对慢性肾脏疾病的遗传病因的整体理解做出贡献。更先进的下一代测序,例如外显子组测序和全面的基因测试面板,正在作为患有慢性肾脏疾病患者的一线诊断方法。使用供体衍生的无细胞DNA(DDCFDNA),已经开发了生物标志物测试,以替代肾脏后移植护理的更具侵入性程序,以优化接枝寿命,同时避免免疫抑制疗法的副作用和毒性。相关政策本政策文件提供了遗传性肾脏疾病的覆盖标准。请参考: