XiaoMi-AI文件搜索系统
World File Search System自动推理

的自动仓库
方法和物质批评:“通过查看数据,我们发现“永远污染项目”采用的“科学”方法是不一致的。知道PFA可以在不同的工业生产中使用,包括“永远的Polyses Project”,假设所有意大利和欧洲纸张的地点都是潜在的污染来源。 “有两个简单的原因。首先是,假设所有生产地点,因此,造纸厂发出的PFA仅仅是因为在过去的数百种甚至数千种不同类型的纸张中,过去可能已经使用了它。其次,仿佛还不够,这也是错误的,因为他复制并粘贴了从权威来源的公司列表“永远的污染项目”明确声明他使用了与Assocarta相关的公司列表,该公司在网站上发表在网站上,作为来源,甚至没有阅读。“如果至少遇到了,就可以避免粗略的错误,如何将行政办公室和技术供应商放在其地图上,这与本文的生产无关。<将其分为换句话说,只需成为Assocarta的成员即可取代作为潜在的污染物。这似乎足以“发布新闻”:最重要的是从内容和方法的角度传播错误的信息” -Sottolinea Medugno。当局和欧洲委员会正在努力使用PFA的法规,这是认真的方法。i“没有偏见,每个人都对自己的陈述承担责任” -Conci Ude Medugno。

臂章:来自自动
大语言模型(LLMS)在一系列文本生成任务中表现出了显着的功能。但是,LLM仍然在需要多步决策和环境反馈的问题上挣扎,例如在线购物,科学推理和数学问题解决。与纯文本数据不同,收集大规模的决策数据具有挑战性。此外,许多功能强大的LLM只能通过API访问,由于成本和复杂性,这阻碍了对代理任务的微调。为了解决LLM代理的局限性,我们提出了一个框架,该框架可以自动从没有人类注释的环境中学习奖励模型。该模型可用于评估LLM代理的动作轨迹并为任务计划提供启发式方法。具体来说,我们的方法涉及使用一个基于LLM的代理随机浏览环境,从而产生各种动作轨迹。随后,利用单独的LLM来分配任务意图,并与每个轨迹的正确响应合成负面响应。然后将这些三胞胎(任务意图,正面响应和负面响应)用作训练数据,以优化能够评分动作轨迹的奖励模型。此奖励模型可以与基于LLM的代理和各种计划算法集成,以增强任务解决性能。通过对不同代理基准进行的评估来证明我们框架的有效性和概括性。总而言之,我们提出的框架代表了增强LLM代理商的决策能力的重要选择。通过自动化奖励模型的学习,我们克服了数据稀缺和API限制的挑战,可能彻底改变了LLM在复杂和交互式环境中的应用。这项研究为更复杂的AI代理铺平了道路,能够解决需要多步骤决策的各种现实世界中的问题。1
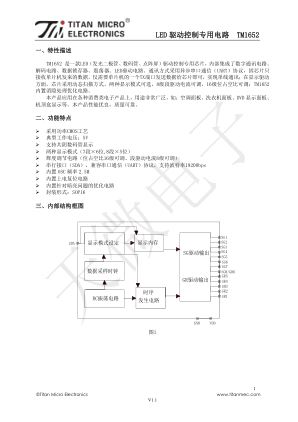
LED 驱动控制专用电路TM1652
Command1~Command n: 发送显示地址命令,地址1~n(最多可设置6个地址) Data1~Data n:发送显示数据(最多6 bytes) Time:数据线置高时间(最小时间为3ms) CommandX:发送显示控制命令(0x18) CommandY:发送显示控制调节命令(包括位占空比、段驱动电流以及显示模式设置) 芯片不需要命令来设置芯片是工作在地址自动加1模式还是固定地址模式,严格来说它只有一种地 址自动加1模式,此处划分是为了更好地说明芯片也可以单独给某个显示寄存器地址写显示数据,如 果单独给某个显示地址写显示数据,写完显示地址后,紧跟着只能写一个显示数据,就把信号线置高 至少3ms,如果紧跟着写几个显示数据,那么芯片在接收到第一个数据后,显示地址就会在规定的地 址上自动加1,再接收第二个显示数据,直到接收到最后一个显示地址的显示数据。

通过机密计算加速 AI 推理
声明和免责声明 1. 在搭载英特尔 SGX 和英特尔 AMX 的第四代至强可扩展处理器上运行 TensorFlow ResNet50 推理工作负载时,性能提升高达 7.57 倍。请参阅下面的配置详细信息。 2. 在搭载英特尔 SGX 和英特尔 AMX 的第四代至强可扩展处理器上运行 Bert-Large 推理工作负载时,性能提升高达 5.26 倍。请参阅下面的配置详细信息。 3. 与上一代相比,在搭载英特尔 SGX 和英特尔 AMX 的第四代英特尔至强可扩展处理器上以 INT8 精度运行 Bert-Large 推理工作负载时,性能提升高达 4.61 倍。请参阅下面的配置详细信息。 4. 在配备英特尔 SGX 和英特尔 AMX 而非 FP32 的第四代英特尔至强可扩展处理器上运行 TensorFlow ResNet50 推理工作负载时,INT8 精度下的性能提升高达 8.02 倍,BF16 精度下的性能提升高达 4.30 倍。请参阅下面的配置详细信息。5. 在配备英特尔 SGX 和英特尔 AMX 而非 FP32 的第四代英特尔至强可扩展处理器上运行 Bert-Large 推理工作负载时,INT8 精度下的性能提升高达 5.46 倍,BF16 精度下的性能提升高达 4.17 倍。请参阅下面的配置详细信息。配置详细信息测试 1:截至 2022 年 11 月 21 日,英特尔进行测试。1 节点、2x 英特尔® 至强® 铂金 8380 CPU @ 2.30GHz、40 个内核、超线程关闭、睿频开启、总内存 512 GB(16x32GB DDR4 3200 MT/s [运行速度为 3200 MT/s])、BIOS 版本 SE5C6200.86B.0022.D64.2105220049、ucode 版本 0xd000375、操作系统版本 Ubuntu 22.04.1 LTS、内核版本 6.0.6-060006-generic、工作负载/基准使用 Fortanix 在安全区域内进行深度学习推理、框架版本 TensorFlow 2.11、模型名称和版本ResNet50v1.5/Bert-Large TEST-2:截至 2022 年 11 月 21 日,英特尔进行测试。1 节点、2x 英特尔® 至强® 铂金 8480+ CPU @ 2.0GHz、56 核、超线程关闭、睿频开启、总内存 512 GB(16x32GB DDR5 4800 MT/s [运行于 4800 MT/s])、BIOS 版本 3A05、ucode 版本 0x2b000070、操作系统版本 Ubuntu 22.04.1 LTS、内核版本 6.0.6-060006-generic、工作负载/基准使用 Fortanix 在安全区域中进行深度学习推理、框架版本 TensorFlow 2.11、模型名称和版本 ResNet50v1.5/Bert-Large 性能因使用情况、配置和其他因素而异。欲了解更多信息,请访问性能指数网站。性能结果基于截至配置中所示日期的测试,可能无法反映所有公开可用的更新。有关配置详细信息,请参阅备份。没有任何产品或组件能够绝对安全。您的成本和结果可能会有所不同。英特尔技术可能需要启用硬件、软件或激活服务。© 英特尔公司。英特尔、英特尔徽标和其他英特尔标志是英特尔公司或其子公司的商标。其他名称和品牌可能是其他财产。

明确主动推理的热力学成本
摘要:在描述主动推理代理 (AIA) 时,“能量”一词可以具有两种不同的含义。一种是 AIA 利用的能量(例如,电能或化学能)。第二个含义是所谓的变分自由能 (VFE),这是一个统计量,它提供了意外的上限。在本文中,我们开发了前一个量——热力学自由能 (TFE)——及其与后者的关系的说明。我们在一个通用的量子信息理论公式中强调了这两者之间的必要权衡,以及这些权衡对生物接近其环境的方式的宏观影响。通过明确这种权衡,我们为从植物到捕食者的生物用来生存的不同代谢策略提供了理论基础。

边缘的神经形态 AI 推理
仅 2020 年,托管云工作负载的数据中心就排放了约 600 兆吨温室气体,超过整个英国 (GB) 的消耗量。除非发生根本性变化,否则到 2050 年,数据中心将消耗全球 20% 以上的能源!凭借其片上学习和低功耗、高吞吐量推理能力,我们相信 AKIDA 可以通过分散 AI 处理来帮助减少数据中心 98% 的碳排放。智能地分析片上数据将有助于终结数百万个端点向云数据中心发送的大量原始、未处理且大多不相关的数据,从而解决阻碍互联网拥塞的问题。

培训推理Hybridq和Pysa是开源的...
(a)通过不同量子门对Pauli运营商(Pauli String)产品的示例转换。单个Pauli字符串𝐼(1)𝜎(2)Z z(3)x𝐼(4)𝐼(4)𝐼(5)被Clifford Gate映射到另一个Pauli字符串中,或通过非clifford门的多个Pauli Strings(未显示)的多个Pauli Strings(未显示的系数)映射到另一个Pauli字符串。(b)单个随机电路实例的OTOC C,用𝑈ˆ,n WV中的非克利福德门的数量测量,固定在不同的值下。虚线是数值模拟结果。对于每个电路,在Q B和Q 1的光锥之间的相交中,在随机位置注入非clifford门。插图显示了Q A(黑色未填充的圆圈),Q 1(黑色填充圆圈)和Q B(蓝色填充圆圈)以及获取数据的电路周期的数量。此处以及图。4,省略了误差线,因为采集了足够数量的样本以确保统计不确定性≤0.01(36)。(c)对于不同的N WV,C的平均值𝐶⎯⎯⎯(顶部)和RMS值C的ΔC(底部)。虚线是从(b)中的数值模拟值计算的。(插图)用于实验电路的时间进化运算符中的Pauli字符串的数值计算的Pauli字符串的平均数量。虚线是指数拟合,𝑛p≈20.96𝑁wv。HybrIDQ用于模拟53个Quarbits,该Qubits用32个非克利福德门模拟。

切换机制的建模和推理方法——...
摘要。要实现能够在自然行为期间跨多个时空尺度进行长期神经记录的神经技术,需要新的建模和推理方法,这些方法可以同时解决两个挑战。首先,这些方法应该从多个记录源(例如脉冲和场电位)汇总所有活动尺度的信息。其次,这些方法应该检测自然场景和长期记录期间行为和/或神经动力学状态的变化。先前的状态检测方法是针对单一活动尺度而不是多尺度活动开发的,先前的多尺度方法没有考虑状态切换并且适用于静止情况。在这里,我们通过开发切换多尺度动力系统模型和相关的过滤和平滑方法来应对这两个挑战。该模型描述了多尺度尖峰场活动中未观察到的大脑状态的编码。它还允许使用未观察到的状态状态进行状态切换动力学,该状态决定每个时间步的动态和编码参数。我们还设计了相关的切换多尺度推理方法,从同时发生的尖峰场活动中估计未观察到的状态和大脑状态。我们在大量数值模拟和记录在猴子身上的前额叶脉冲场数据中验证了这些方法,猴子为了获得流体奖励而进行扫视。我们表明,这些方法可以成功地结合脉冲和场电位观测,同时准确地跟踪状态和大脑状态。这样,与单尺度切换方法或固定多尺度方法相比,这些方法可以更好地估计状态。这些建模和推理方法有效地结合了状态检测和多尺度观测。因此,它们可以促进对潜在切换神经群体动态的研究,并通过在出现状态依赖的多尺度活动和行为的自然场景中进行推理来改善未来的脑机接口。

定量推理问题和回答主要5
**定量推理考试问题**以下问题来自各种考试,包括第二学期考试和5年级学生的第三学期考试。**部分D(第三学期检查)**1。如果“礼堂”由代码表示,那么什么数字代表“鼓”一词?a)3782 b)3278 c)3728 2。代码“ 671567”代表什么?A)Odator B)演说者C)Roator 3。您将如何在代码中写“叛徒”一词?a)5741576 b)5714567 c)5714657 4。“电机”一词的代码是什么?a)86567 b)86565 c)86756 5。代码“ 7465”表示哪个单词?a)ROIT b)riom c)RIOT **部分E(第三学期检查)**1。如果5 + 11 + 10 =?,方程的值是多少?A)7 B)10 C)25 D)15 E)30 2。方程的值是多少?+ 11 + 4 + 1 + 5 =?A)15 B)10 C)1 D)0 E)2 3。如果32 + 111 + 4 + 11 + 2 =?,方程的值是多少?a)10 b)38 c)98 d)4 e)6 4。方程1 +的值是多少?= 8?a)14 b)16 c)10 d)12 e)7 5。如果?+ 111 + 5 = 8,方程的值是多少?a)30 b)40 c)20 d)50 e)60提供的文本是针对小学5名学生量身定制的样本定量推理问题及其解决方案的集合。它也是教师更有效地创建考试和考试问题的参考材料,并帮助学生评估他们的考试水平。问题包括正确的答案。定量推理评估个人应用数学或分析技能来解决问题的能力,有助于理解解决尼日利亚小学学生推荐的教科书问题背后的逻辑。提供了示例解决方案,涵盖了各种格式,例如基本算术操作,乘法和除法以及涉及方形和基本代数的更复杂的计算。文本分为几个示例(示例1至8),展示了不同类型的定量推理问题,包括: - 使用数学公式来解决具有扭曲的简单算术操作。- 求解涉及正方形,根和其他基本代数函数的方程式。- 基本乘法和分裂,重点是理解所使用的模式或公式。- 识别数组中列之间的模式。目标是证明如何将这些原则应用于各种问题,包括前3、4和5名学生的过去考试中的问题。37 76/2 + 6 = 44上述格式应用于解决问题。例如,第一个样本的10个解决方案,格式为(2+2+1+3)*3 = 24 0+4+3+6)*3 = 39(4+1+2+4)*3 = 33 = 33您在图的边缘添加所有数字,并乘以3。对于第二个样本,2*8 = 12+4 = 16 5*9 = 17+28 = 45 7*7*7 = 25+24 = 49示例11从示例中,25/5 = 5,20-10 = 10,然后添加两个答案5+10 = 15,这是中间的数字。对于第二个,39/13 = 3,46-18 = 28 so 28+3 = 31。如果您对定量推理有任何疑问,可以通过Twitter或我的WhatsApp(09059059123)与我联系。For the third one, 44/2 = 23, 11-6 = 5, so 23+5 = 28 Example 12 For sample 1, (2^2 + 5^2) -(3^2 + 2^2) = 16 4 +25) – (9+4) = 16 29-13 = 16 For sample 2, (3^2 + 1^2) – (1^2 + 2^2) = 5 9 + 1) – (1 + 4) = 5 10 - 5 = 5 For sample 3,(5^2 + 5^2) - (4^2 + 2^2)= 30 25 + 25) - (16 + 4)= 30 50 - 20 = 30,因此,您可以使用上述方法来解决其余问题。

多阶段推理:解锁认知自主权...
如前所述,依靠静态预训练数据完成任务的体系结构缺乏集成跨模式数据的能力(Ye等,2023)。当人形机器人处理听力,触摸或反应不一致时,这直接引起语义歧义(Pramanick&Rossi,2024)。尽管某些研究尝试了多模式融合技术,但进展仍然有限,不足以为人形机器人提供与人类相同的适应能力(Yuan等,2024)。为了解决这一差距,这项研究提出了一个多幕科推理体系结构作为创新解决方案。它旨在利用多幕科推理来优化类人类机器人在当前技术缺点基于视觉,听觉和触觉数据的跨模式中认知自主权的关键挑战。