
机构名称:
¥ 2.0
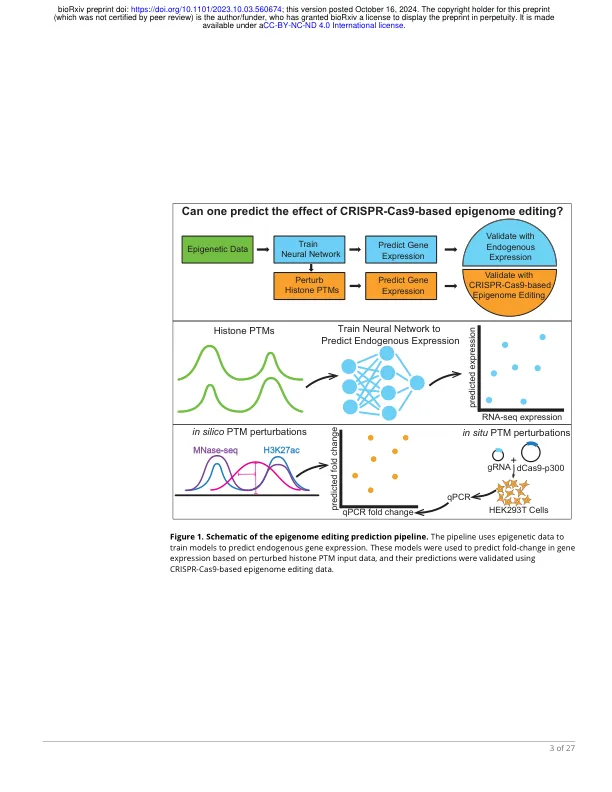
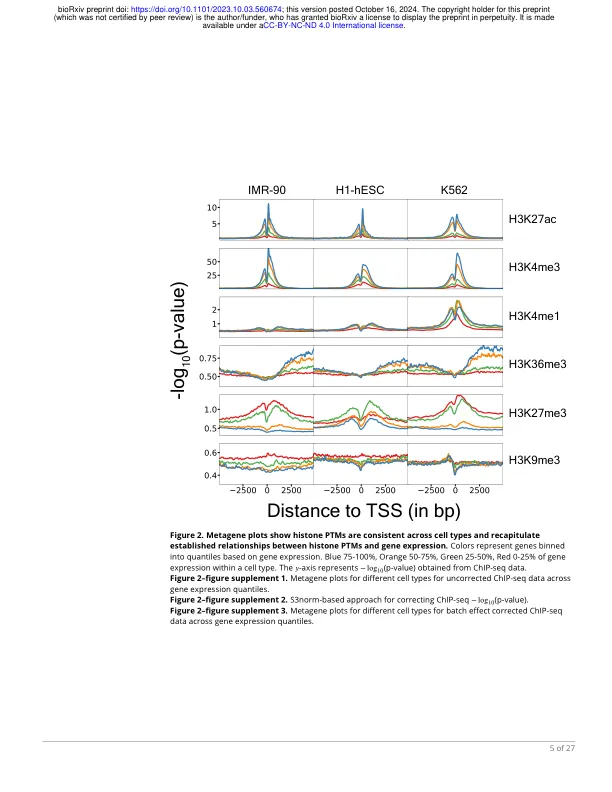
摘要表观遗传调控协调哺乳动物转录,但它们之间的功能联系仍然难以捉摸。为了解决这个问题,我们使用来自 13 种 ENCODE 细胞类型的表观基因组和转录组数据来训练机器学习模型,以预测组蛋白翻译后修饰 (PTM) 的基因表达,对于大多数细胞类型,实现了 ∼0.70 −0.79 的转录组范围相关性。我们的模型重现了组蛋白 PTM 和表达模式之间的已知关联,包括预测转录起始位点 (TSS) 附近的组蛋白亚基 H3 赖氨酸残基 27 (H3K27ac) 的乙酰化会显著提高表达水平。为了通过实验验证这一预测,并研究 H3K27ac 的天然沉积与人工沉积对表达的影响,我们将合成的 dCas9-p300 组蛋白乙酰转移酶系统应用于 HEK293T 细胞系中的 8 个基因和 K562 细胞系中的 5 个基因。此外,为了便于建立模型,我们执行 MNase-seq 来绘制 HEK293T 中全基因组核小体占有水平。我们观察到,我们的模型在准确排序基因对 dCas9-p300 系统的相对倍数变化方面表现良好;然而,与根据其天然表观遗传特征预测跨细胞类型的表达相比,它们对单个基因内倍数变化进行排序的能力明显减弱。我们的研究结果强调,我们需要更全面的基因组规模表观基因组编辑数据集,更好地理解表观基因组编辑工具所做的实际修改,以及改进因果模型,以便更好地从内源性细胞测量转移到扰动实验。这些改进将共同促进理解和可预测地控制动态人类表观基因组的能力,以及对人类健康的影响。
预测基于 CRISPR-Cas9 的表观基因组编辑的效果
主要关键词



相关文件推荐





























