机构名称:
¥ 2.0
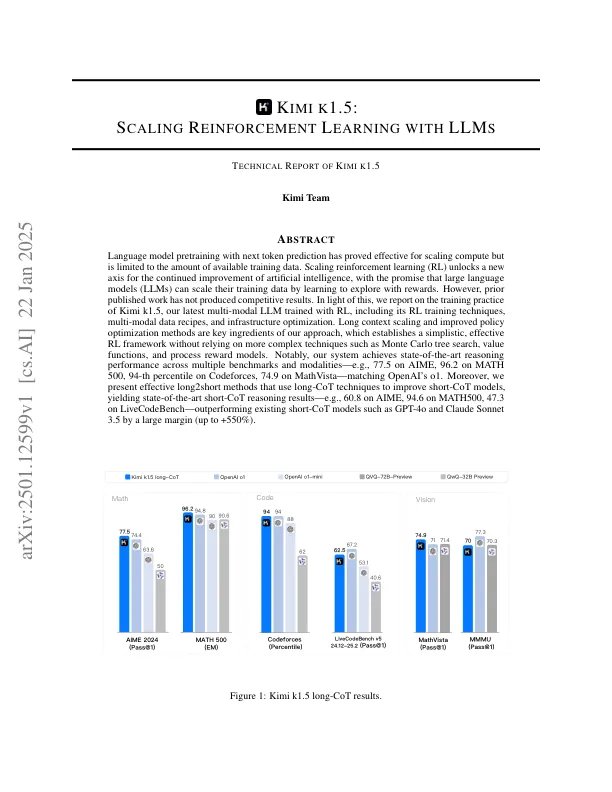
对次要标记预测进行预处理的语言模型已被证明对缩放计算有效,但仅限于可用培训数据的数量。缩放增强学习(RL)为继续改善人工智能的新轴解锁了新的轴,并承诺大型语言模型(LLMS)可以通过学习奖励来探索探索的培训数据。但是,事先发表的工作尚未产生竞争成果。鉴于此,我们报告了Kimi K1.5的培训实践,Kimi K1.5是我们接受RL培训的最新多模式LLM,包括其RL培训技术,多模式数据配方和基础架构优化。长上下文缩放和改进的策略优化方法是我们方法的关键要素,它可以建立一个简单,有效的RL框架,而无需依赖更复杂的技术,例如蒙特卡洛树搜索,价值功能和过程奖励模型。值得注意的是,我们的系统在多个基准和模态上实现了最先进的推理性能,例如,Aime上的77.5,在数学500上为96.2,在Mathvista上为74.9,在数学500上为94%,在Mathvista上为74.9,匹配OpenAi的O1。此外,我们提供了有效的长期2个方法,这些方法使用长期技术来改善短框模型,从而产生最先进的短点推理结果 - 例如,在Aime上,Math500,47.3上的94.6在livecodebench上 - 在livecodebench上 - 以gpt-4o和claude sonnnet +550 +550 +550 / claude sonnnet +550 / claude sonnnet。
Kimi K1.5:使用LLMS缩放加强学习
主要关键词




相关文件推荐