
机构名称:
¥ 1.0
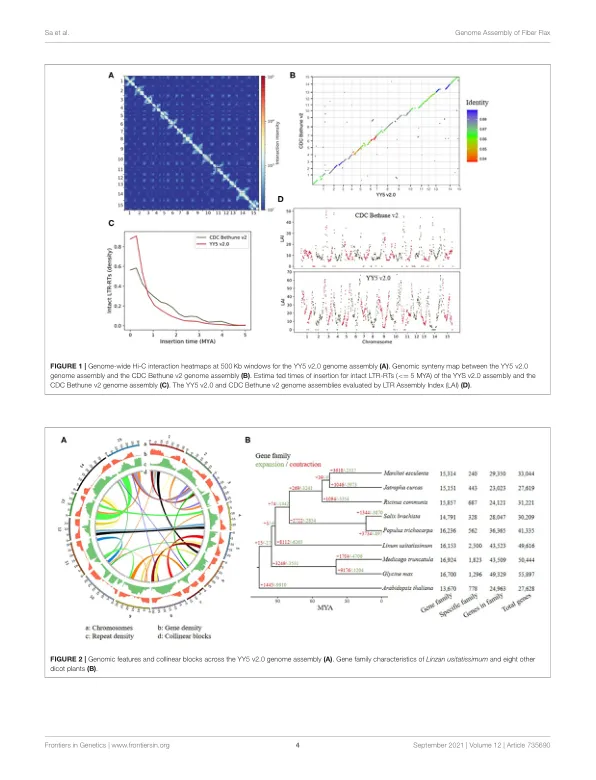
亚麻 ( Linum usitatissimum ) 也称为普通亚麻或亚麻籽,在温带地区作为油料和纤维作物种植,可能已被人类使用长达 30,000 年 ( Kvavadze et al., 2009 )。纤维亚麻是栽培亚麻的主要形态类型之一,也是驯化作物中最古老的形态,为人类提供了纤维来源 ( Hickey, 1988 )。据报道,对纤维亚麻 ( 纤维用途 ) 和亚麻籽亚麻 ( 油料用途 ) 的破坏性选择导致植物类型在形态、解剖学、生理学和农艺性能上存在很大差异 ( Diederichsen and Ulrich, 2009 )。纤维亚麻比油料用途亚麻相对较高、分枝较少、种子较少 ( Zhang et al., 2020 )。在过去十年中,纤维工业开发出高价值产品,应用于汽车、建筑工业、生物燃料工业和纸浆(Diederichsen 和 Ulrich,2009 年)。亚麻制成的纺织品在西方国家被称为亚麻布,传统上用于床单、内衣和桌布。亚麻仍然是一种小作物,主要原因是过去十年来其产量过低(Soto-Cerda 等人,2014 年)。准确的参考基因组已成为遗传学研究不可或缺的资源,尤其是对于功能基因图谱和标记辅助选择(MAS)。亚麻基因组的组装可以显著加速亚麻育种的进程。受益于亚麻参考基因组的发布,人们获得了不少与重要农艺性状相关的候选基因 ( Soto-Cerda et al., 2018; Xie et al., 2018a,b; You et al., 2018b; Guo et al., 2020 )。第一个亚麻基因组组装于 2012 年使用 Illumina 短双端和配对读段 (CDC Bethune v1) 发布 ( Wang et al., 2012 )。随后,You 等人使用光学、物理和遗传图谱 (CDC Bethune v2) 将这些碎片化的重叠群锚定到 15 个假分子中 ( You et al., 2018a )。最近还使用短双端读段和 Hi-C 测序发布了三个不同品种的基因组组装 ( Zhang et al., 2020 )。几个月前首次发表了使用错误长读长的亚麻组装体(Dmitriev et al., 2021)。然而,即使使用 Oxford Nanopore 长读技术,所有这些组装体的连续性都非常差。这些组装体最大的重叠群 N50 为 365 Kb。亚麻基因组最近经历了全基因组复制 (WGD) 事件,充满了重复元素(You et al., 2018a)。在使用短读长或错误长读长的组装过程中,同源序列或重复序列之间很容易发生崩溃。使用不同的软件和 Oxford Nanopore 长读长组装体,组装体大小差异很大,证明了这一点(Dmitriev et al., 2021)。
亚麻 (Linum usitatissimum) 基因组的染色体水平组装和注释
主要关键词




相关文件推荐





























