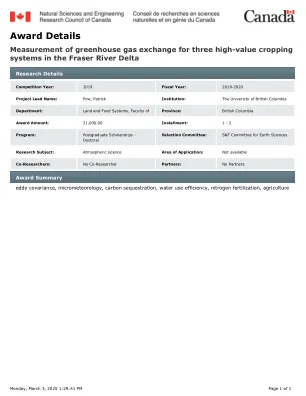
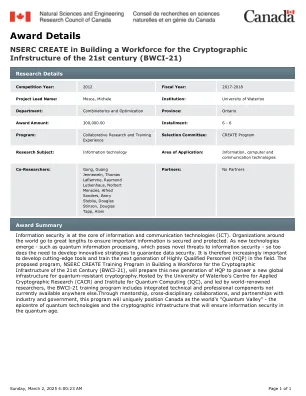
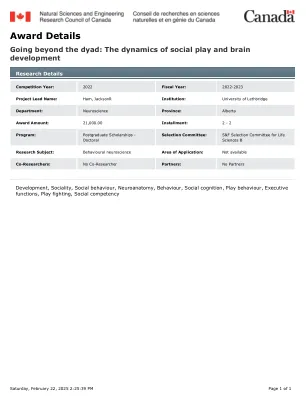
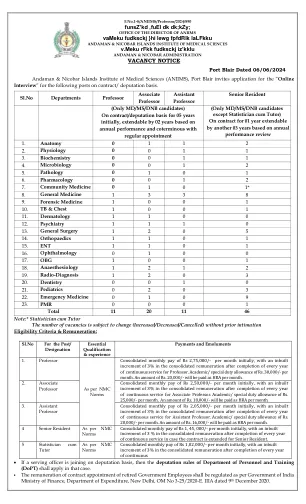
机构名称:
¥ 1.0
几个世纪以来,人类一直试图了解智力及其相关的机制,这些机制推动了我们的思维方式。有些人假设有不同类型的能力需要不同的信号或目标,包括学习,感知,社会智力,概括和模仿,但其他人则建议通过反复试验和错误学习以最大程度地提高奖励,这可以帮助发展包含所有这些能力的能力。在本文中,我们认为,尽管最大化奖励是发展各种能力范围的核心,但我们必须重新构架这些奖励的方式和制定这些奖励的方式,因为在增强学习中使用奖励的常规方法可能是令人难以置信的,并且在各种环境中都表现不佳,包括稀疏环境和嘈杂的奖励条件。我们建议需要对这些奖励进行改革,以纳入i)不确定性的不同概念,ii)人类偏好,iii)嵌套或混合的组成,iv)非平稳性,并说明v)无需奖励的情况。我们建议这样做可以使更强大的强化学习者成为迈向人工通用情报的一步。
奖励几乎是足够的
主要关键词





相关文件推荐