
机构名称:
¥ 2.0
本文介绍了一个全面的基准测试套件,该套件是针对离线安全增强学习(RL)挑战的全面的,旨在促进培训和部署阶段中安全学习算法的发展和评估。我们的基准套件包含三个包:1)精心制作的安全政策,2)D4RL风格的数据集以及环境包装器,以及3)高质量的离线安全RL基线实施。我们采用有条不紊的数据收集管道,该管道由先进的安全RL算法启动,该管道有助于从机器人控制到自动驾驶的38个流行的安全RL任务中跨38个流行的安全RL任务的不同数据集的生成。我们进一步引入了一系列数据后处理过滤器,能够修改每个数据集的多样性,从而模拟各种数据收集条件。此外,我们还提供了普遍的离线安全RL算法的优雅且可扩展的实现,以加速该领域的研究。通过超过50000个CPU和800 GPU小时计算的广泛实验,我们评估和比较了这些基线算法在收集的数据集中的性能,从而提供了有关其优势,局限性和潜在改进领域的见解。我们的基准测试框架是研究人员和从业人员的宝贵资源,促进了在安全性应用中开发更健壮和可靠的离线安全RL解决方案。基准网站可在www.offline-saferl.org上找到。
离线安全加固学习的数据集和基准
主要关键词




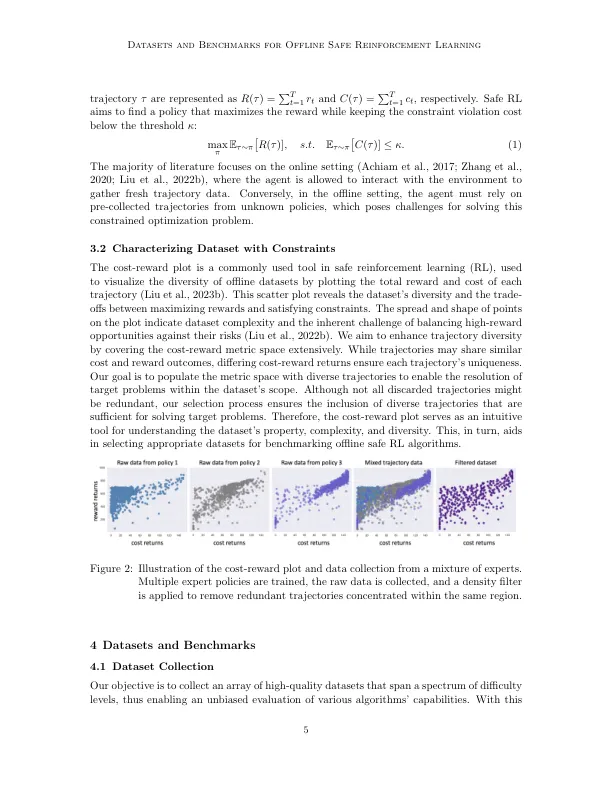
相关文件推荐





























