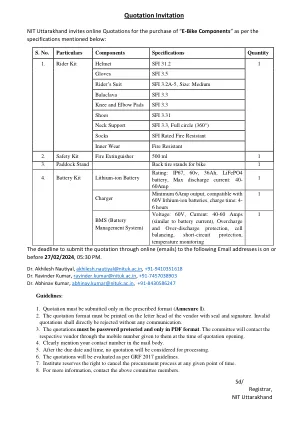
机构名称:
¥ 3.0
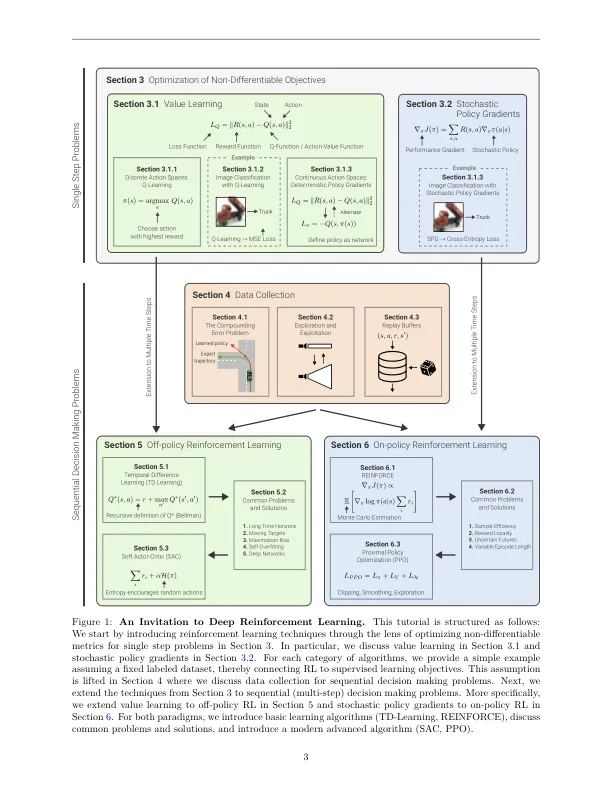
培训深层神经网络以最大化目标目标已成为过去十年中成功的机器学习的标准配方。如果目标目标是可区分的,则可以通过监督学习来优化这些网络。对于许多有趣的问题,事实并非如此。共同的目标,例如联合(IOU)的交集,双语评估研究(BLEU)得分或奖励,无法通过超级学习的学习来优化。一个常见的解决方法是定义可区分的替代损失,从而导致相对于实际目标的次优解决方案。强化学习(RL)已成为一种有希望的替代方法,用于优化深层神经网络,以最大程度地提高非微分目标。示例包括通过人类反馈,代码生成,对象检测或控制问题对齐大语言模型。这使得RL技术与较大的机器学习受众相关。然而,由于大量方法以及通常非常理论上的呈现,该主题是在接近的时间密集。在此简介中,我们采用另一种方法,不同于经典的加强学习教科书。我们不关注表格问题,而是引入强化学习作为监督学习的概括,我们首先将其应用于非差异性目标,后来又适用于时间问题。在阅读本教程后,读者只有受监督学习的基本知识,读者将能够理解最先进的深度RL算法(例如近端策略优化(PPO))。
深入加固学习的邀请
主要关键词




相关文件推荐