机构名称:
¥ 2.0
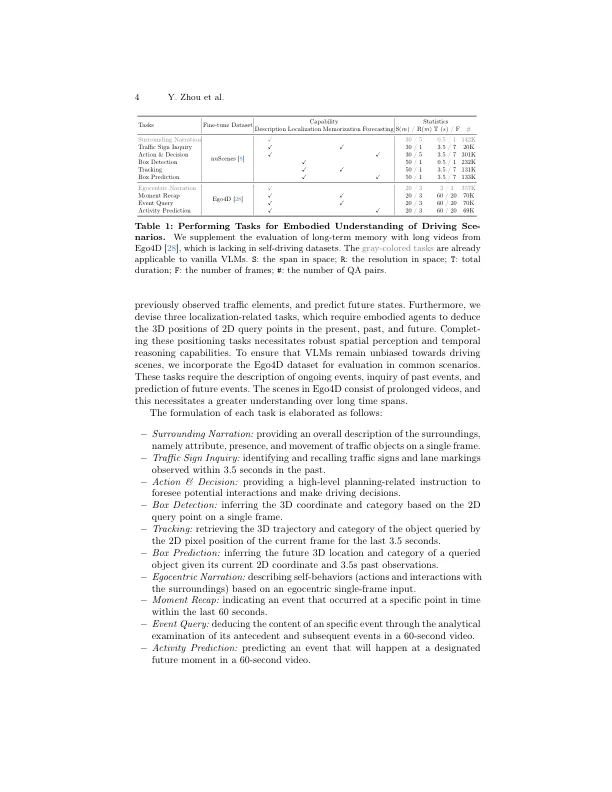
摘要。体现的场景理解是自主代理人感知,解释和应对开放驾驶场景的基石。这种理解通常建立在视觉模型(VLM)上。尽管如此,现有的VLM仅限于2D领域,没有空间意识和长匹马外推过程。我们重新审视了自主驾驶和适当的专栏的关键方面。特此,我们介绍了体现语言模型(ELM),这是一个针对代理商量身定制的综合框架,该框架对具有较大空间和暂时的跨度的驾驶场景的理解。ELM结合了空间感知的预训练,以赋予代理具有强大的空间定位功能。此外,该模型还采用时间感知的令牌选择来准确询问时间提示。我们可以在重新重新的多面基准上实现Elm,并且在各个方面都超过了先前的最新方法。所有代码,数据和模型均可在https://github.com/opendrivelab/elm上访问。
体现了对驾驶场景的理解
主要关键词




相关文件推荐