机构名称:
¥ 2.0
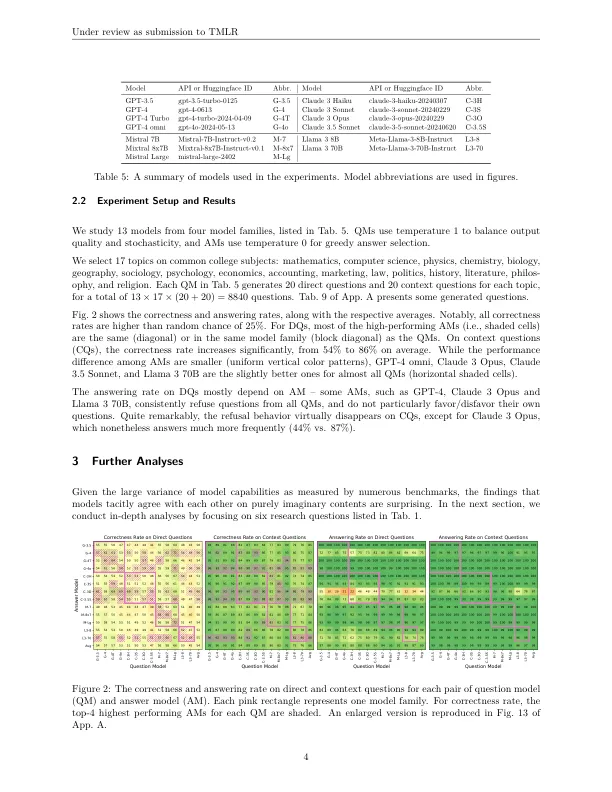
尽管最近大语言模型(LLM)的扩散,但他们的培训配方 - 模型架构,培训数据和优化算法 - 通常非常相似。这自然提出了所得模型之间相似性的问题。在此过程中,我们提出了一个新颖的设置,虚构的问题回答(IQA),以更好地理解模型相似性。在IQA中,我们要求一个模型生成纯粹的虚构问题(例如,在物理学中的完全构成概念上),并促使另一个模型回答。令人惊讶的是,尽管这些问题完全是虚构的,但所有模型都可以以显着的一致性来回答彼此的问题,这表明了这些模型在此类幻觉中运行的“共同想象空间”。我们对这种现象进行了一系列研究,并讨论了这种模型均匀性对幻觉检测和计算创造力的含义。我们将在公共网站上发布并维护代码和数据。
共享的想象力:LLMS幻觉
主要关键词




相关文件推荐