机构名称:
¥ 1.0
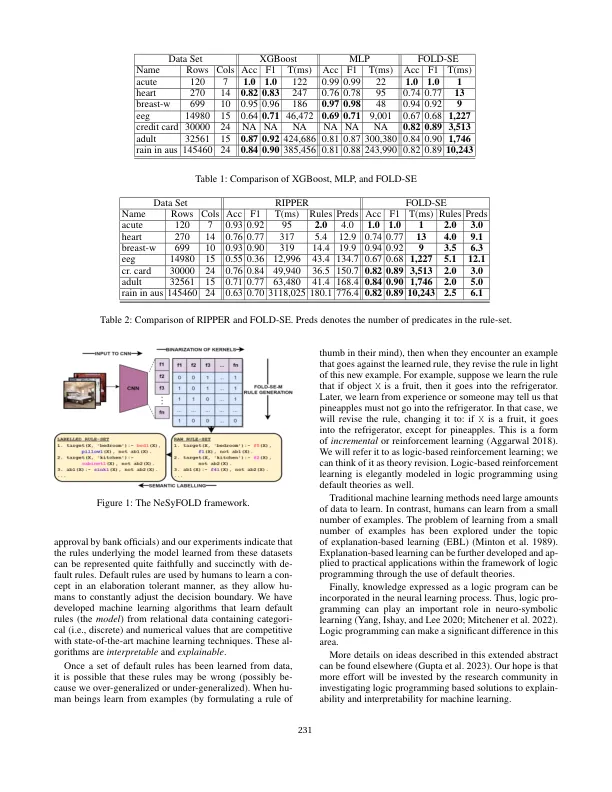
在ILP中也以非单调逻辑程序和默认规则(Srinivasan,Muggleton和Bain 1992; Dimopoulos and Kakas 1995)学习了身体中的目标。将模型表示为默认规则带来了可观的优势,可解释性,增量学习和数据经济。我们提出了可解释和可解释的基于LP的机器学习算法,以及用于增量学习的基于LP的强化学习,以及基于LP-基于LP的解释,用于解决数据经济问题。我们可解释的基于LP的机器学习方法(Shakerin,Salazar和Gupta 2017; Wang and Gupta 2022,2024)与最先进的技术竞争,例如XGBOOST(Chen and Guestrin 2016)和Mult-ceptrons/ceptrons/nealurations/nealuret网络(Aggarwal 2018)。表1显示了基于LP的ML算法的Fold-SE(Wang and Gupta 2024)的性能比较,以及XG-BOOST和MLP在二进制分类任务上的性能比较。与其他可解释的ML算法不同的是,它可以从数据中学习基于简洁的逻辑规则集,然后可以使用该规则集来进行预测。表2显示了Fold-SE与另一个流行的可解释的ML算法Ripper的比较。fold-se在产生明显较小的规则集的同时,达到了更高或可取的精度。nesyfold(Padalkar,Wang和Gupta 2023; Padalkar and Gupta 2023)是一个使用Fold-Se-M算法(用于多类别分类)的框架,从对图像分类任务进行培训的CNN生成全局解释。对于整个火车组,将最后一层内核的输出进行了二元。然后使用折叠-SE-M算法来学习一个规则集,其中每个谓词的真实值都被二进制内核的输出确定。每个内核都可以映射到它所学会的概念中,可以将其识别为识别及其相应的谓词可以将其标记为这些概念。图1说明了用于对“浴室”,“床房”和“厨房”的图像进行分类的CNN的Nesyfold框架。可以通过域专家仔细检查获得的规则集,以检查CNN可能学到的偏见。默认规则是捕获关系数据集的逻辑的绝佳方法。人类在日常推理中使用默认值(Stenning and van Lambalgen 2008; Dietz Saldanha,Houldobler和Pereira 2021)。大多数数据集都是由人类驱动的活动产生的(例如贷款
基于逻辑的可解释和增量机器学习
主要关键词


相关文件推荐