
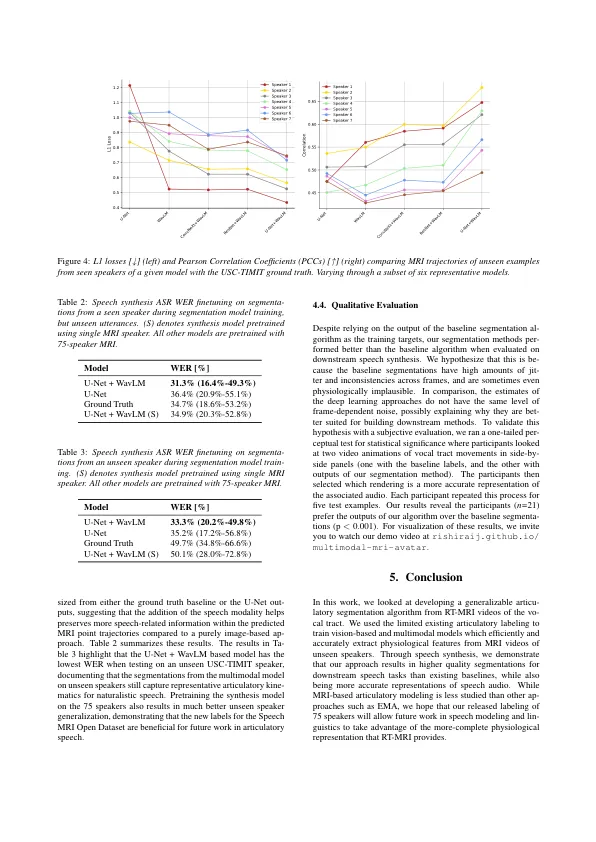
机构名称:
¥ 1.0
对声带的准确建模对于构建可解释的语音处理和语言学的关节表达是必要的。但是,声带建模是具有挑战性的,因为许多内部铰接器都被外部运动捕获技术遮住了。实时磁共振成像(RT-MRI)允许在语音过程中测量膜枢纽器的精确运动,但是由于耗时和计算昂贵的标记方法,带注释的MRI数据集限制了大小。我们首先使用仅视觉分段的方法为RT-MRI视频提供了深刻的标签策略。然后,我们使用音频引入多模式算法,以改善人声铰接器的分割。一起,我们为MRI视频细分中的声带建模设定了一个新的基准测试,并使用它来发布75个扬声器RT-MRI数据集的标签,从而将人声道标记的公共RT-MRI数据增加到9。代码和数据集标签可以在rishiraij.github.io/ mult-opodal-mri-avatar/。索引术语:发音演讲,视听感知
声带建模的多模式分割
主要关键词




相关文件推荐





























