机构名称:
¥ 4.0
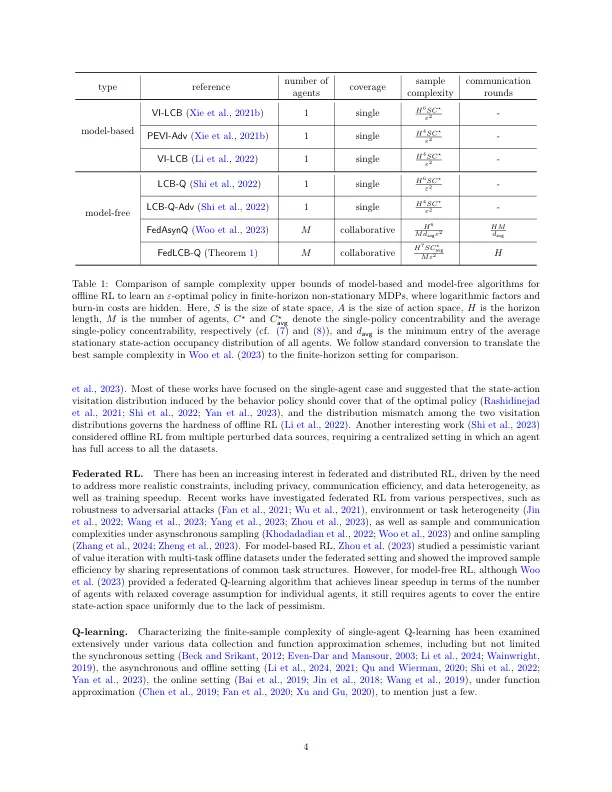
离线增强学习(RL)试图使用离线数据学习最佳策略,由于其在在线数据收集不可行或昂贵的关键应用程序中的潜力,因此引起了极大的兴趣。这项工作探讨了联合学习对离线RL的好处,旨在协作利用多个代理商的离线数据集。专注于有限的情节表格马尔可夫决策过程(MDPS),我们设计了FedLCB-Q,这是针对联合离线RL量身定制的流行无模型Q学习算法的变体。FedLCB-Q更新了具有新颖的学习率时间表的代理商的本地Q-功能,并使用重要性平均和精心设计的悲观惩罚项将其在中央服务器上汇总。Our sample complexity analysis reveals that, with appropriately chosen parameters and synchronization schedules, FedLCB-Q achieves linear speedup in terms of the number of agents without requiring high-quality datasets at individual agents, as long as the local datasets collectively cover the state-action space visited by the optimal policy, highlighting the power of collaboration in the federated setting.实际上,样本复杂性几乎与单代理对应物的复杂性匹配,好像所有数据都存储在中心位置,直到地平线长度的多项式因子。此外,fedlcb-Q是通信有效的,其中通信弹的数量仅相对于地平线长度与对数因素有关。
联合离线加固学习:协作单政策的覆盖范围就足够
主要关键词




相关文件推荐