
机构名称:
¥ 1.0
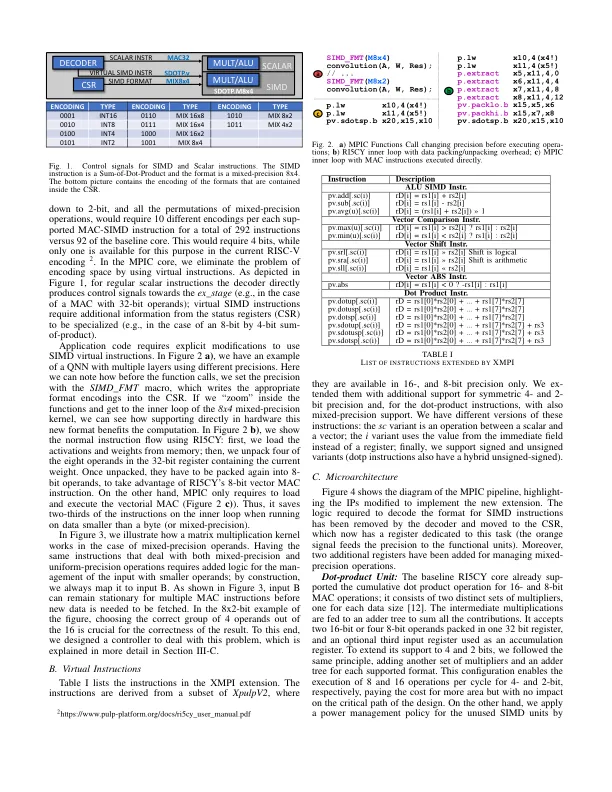
摘要 — 低位宽量化神经网络 (QNN) 通过减少内存占用,支持在受限设备(如微控制器 (MCU))上部署复杂的机器学习模型。细粒度非对称量化(即,在张量基础上为权重和激活分配不同的位宽)是一种特别有趣的方案,可以在严格的内存约束下最大限度地提高准确性 [1]。然而,SoA 微处理器缺乏对子字节指令集架构 (ISA) 的支持,这使得很难在嵌入式 MCU 中充分利用这种极端量化范式。对子字节和非对称 QNN 的支持需要许多精度格式和大量的操作码空间。在这项工作中,我们使用基于状态的 SIMD 指令来解决这个问题:不是显式编码精度,而是在核心状态寄存器中动态设置每个操作数的精度。我们提出了一种基于开源 RI5CY 核心的新型 RISC-V ISA 核心 MPIC(混合精度推理核心)。我们的方法能够完全支持混合精度 QNN 推理,具有 292 种不同的操作数组合,精度为 16 位、8 位、4 位和 2 位,而无需添加任何额外的操作码或增加解码阶段的复杂性。我们的结果表明,与 RI5CY 上的基于软件的混合精度相比,MPIC 将性能和能效提高了 1.1-4.9 倍;与市售的 Cortex-M4 和 M7 微控制器相比,它的性能提高了 3.6-11.7 倍,效率提高了 41-155 倍。索引术语 —PULP 平台、嵌入式系统、深度神经网络、混合精度、微控制器
用于极边缘 DNN 推理的混合精度 RISC-V 处理器
主要关键词




相关文件推荐





























