机构名称:
¥ 2.0
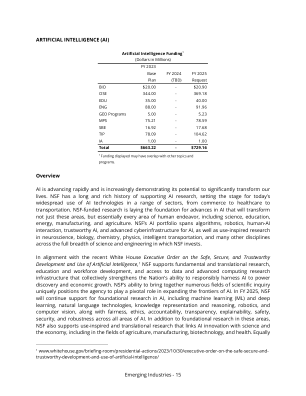
模型 BERT BERT 6B Dense Dense Dense ViT ViT ViT ViT ViT 微调预训练 Transf。 121 169 201 微型 小型基础 大型 巨型 GPU 4 · V100 8 · V100 256 · A100 1 · P40 1 · P40 1 · P40 1 · V100 1 · V100 1 · V100 4 · V100 4 · V100 小时 6 36 192 0.3 0.3 0.4 19 19 21 90 216 千瓦时 3.1 37.3 13,812.4 0.02 0.03 0.04 1.7 2.2 4.7 93.3 237.6 表 2. 对于我们分析的 11 个模型:GPU 的类型、该类型的 GPU 数量、小时数以及所用的能量(千瓦时)。例如,我们的 BERT 语言建模 (BERT LM) 实验使用了 8 个 V100 GPU,持续了 36 个小时,总共使用了 37.3 千瓦时。我们注意到,60 亿参数转换器的训练运行时间仅为训练完成时间的约 13%,我们估计完整的训练运行将消耗约 103,593 千瓦时。
测量云实例中人工智能的碳强度
主要关键词





相关文件推荐