
机构名称:
¥ 1.0
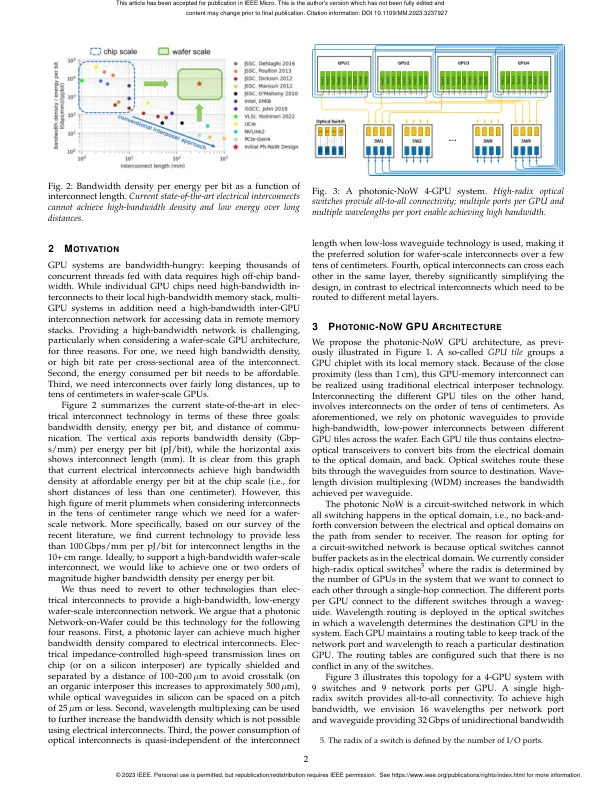
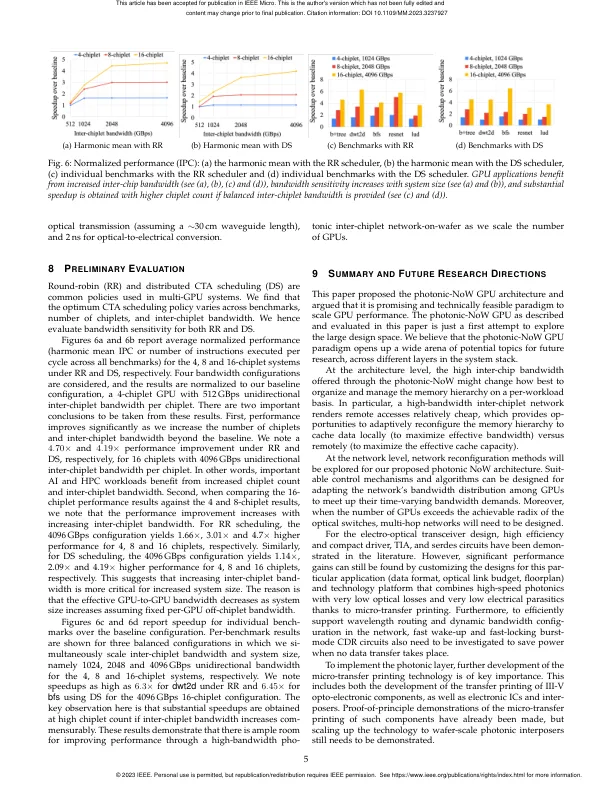
在过去十年中,图形处理单元 (GPU) 的进步推动了人工智能 (AI)、高性能计算 (HPC) 和数据分析领域的重大发展。要在这些领域中的任何一个领域继续保持这一趋势,就需要能够不断扩展 GPU 性能。直到最近,GPU 性能一直是通过跨代增加流式多处理器 (SM) 的数量来扩展的。这是通过利用摩尔定律并在最先进的芯片技术节点中使用尽可能多的晶体管数量来实现的。不幸的是,晶体管的缩放速度正在放缓,并可能最终停止。此外,随着现代 GPU 接近光罩极限(约 800 平方毫米),制造问题进一步限制了最大芯片尺寸。而且,非常大的芯片会导致产量问题,使大型单片 GPU 的成本达到不理想的水平。GPU 性能扩展的解决方案是将多个物理 GPU 连接在一起,同时向软件提供单个逻辑 GPU 的抽象。一种方法是在印刷电路板 (PCB) 上连接多个 GPU。由于提供的 GPU 间带宽有限,在这些多 GPU 系统上扩展 GPU 工作负载非常困难。封装内互连(例如通过中介层技术)比封装外互连提供更高的带宽和更低的延迟,为将 GPU 性能扩展到少数 GPU 提供了一个有希望的方向 [1]。晶圆级集成更进一步,通过将预制芯片粘合在硅晶圆上,为具有数十个 GPU 的晶圆级 GPU 提供了途径 [2]。不幸的是,使用电互连在长距离上以低功耗提供高带宽密度从根本上具有挑战性,从而限制了使用电中介层技术进行 GPU 扩展。在本文中,我们提出了光子晶圆网络 (NoW) GPU 架构,其中预先制造和预先测试的 GPU 芯片和内存芯片安装在晶圆级中介层上,该中介层通过光子网络层连接 GPU 芯片,同时将每个 GPU 芯片与其本地内存堆栈电连接,如图 1 所示。光子-NoW GPU 架构的关键优势在于能够在相对较长的晶圆级距离(高达数十厘米)内以低功耗实现高带宽密度。本文的目标是展示光子-NoW 的愿景
用于多芯片 GPU 的晶圆光子网络
主要关键词



相关文件推荐





























