机构名称:
¥ 1.0
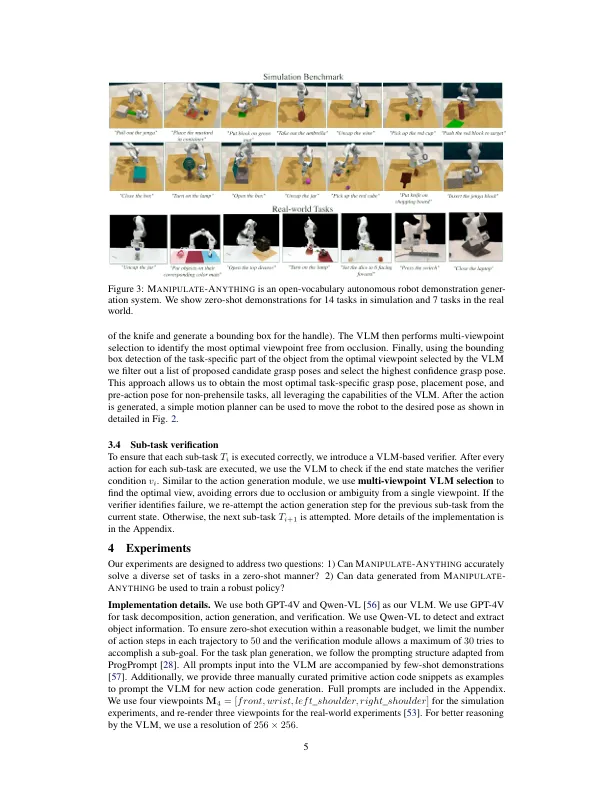
摘要:RT-1 [1]和广泛的社区努力(例如Open-X-敌人[2])的大规模努力[2]有助于增加机器人演示数据的规模。但是,仍然有机会提高机器人演示数据的质量,数量和多样性。尽管已证明视觉模型可以自动生成演示数据,但它们的效用仅限于具有特权状态信息的环境,它们需要手工设计的技能,并且仅限于与几乎没有对象实例的交互。我们提出了一种nything,这是一种可扩展的自动生成方法,用于现实世界机器人操纵。与先前的工作不同,我们的方法可以在实际环境中运行,而无需任何特权状态信息,手工设计的技能,并且可以操纵任何静态对象。我们使用两个设置评估我们的方法。首先,m anipulate -a nything成功地生成了所有7个现实世界和14个仿真任务的轨迹,显着优于诸如voxposer之类的现有方法。第二,与人类示威的训练或从voxposer [3],扩展[4]和代码 - 质量[5]产生的数据相比,与训练人的训练相比,可以训练更健壮的行为克隆策略可以训练更健壮的行为克隆策略。我们认为,nything可以是生成用于机器人技术的数据的可扩展方法,也可以是零射击设置中的新任务。项目页面:robot-ma.github.io。
nything:使用视觉语言模型自动化现实世界机器人
主要关键词




相关文件推荐