
机构名称:
¥ 1.0
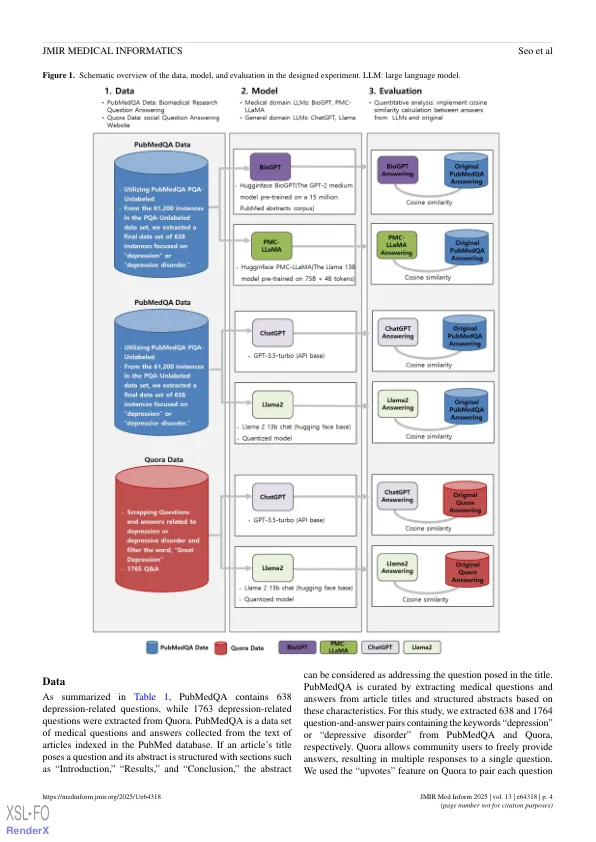
图1提供了研究设计的示意图。这项研究包括3个组成部分:数据,模型和评估。模型根据数据类型而变化,而评估方法在整个过程中保持一致。数据分为两种类型:PubMedQA,源自医学研究摘要,以及从Quora [41-43]中提取的问答数据,这是一个社交平台,用户提出和回答问题。实验中使用的模型包括两种类型:经过预处理的基本模型和一个对医学数据进行微调的模型。为了评估每个模型的生成答案,我们检查了与输入问题有关的响应的数量和质量。随后,我们评估了正确答案的生成答案的相似性。bert的相似性[36]和Spacy相似性[37]用于测量每个与抑郁症相关问题的人提供的原始答案与LLM生成的答案之间的上下文相似性。
XSL•fo
主要关键词




相关文件推荐
















