
机构名称:
¥ 1.0
摘要:亲自识别,重新排列是通过完善检索结果的初始排名来提高整体准确性的关键步骤。先前的研究主要集中在单视图像的特征上,这些特征可能会导致偏见和诸如姿势变化,观点变化和遮挡等问题。使用多视图来介绍一个人可以帮助减少视图偏差。在这项工作中,我们提出了一种有效的重新级别方法,该方法通过使用K-Neartivt加权融合(KWF)方法来汇总邻居的功能来生成多视图特征。具体来说,我们假设从重新识别模型中提取的特征在表示相同的身份时高度相似。因此,我们以无监督的方式选择K相邻功能来生成多视图功能。此外,本研究探讨了特征聚合过程中的重量选择策略,从而使我们能够确定有效的策略。我们的重新排列方法不需要模型进行微调或额外的注释,因此它适用于大规模数据集。我们在重新识别数据集Market1501,MSMT17和遮挡的dukemtmc上评估我们的方法。结果表明,从初始排名结果中重新列出顶级M候选者时,我们的方法会显着提高列表@1并映射。具体而言,与初始结果相比,我们的重新排列方法在具有挑战性的数据集中,等级@1的提高分别为9.8% / 22.0%:MSMT17和闭塞性dukemtmc。此外,我们的方法证明了与其他重新排列方法相比,计算效率的实质性提高。
使用k-neartift加权融合的人重新识别*
主要关键词




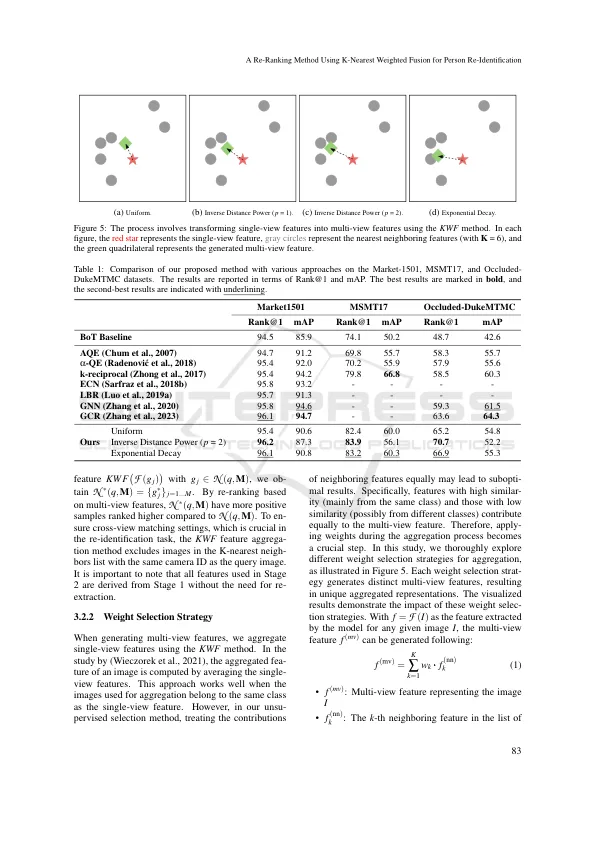
相关文件推荐





























