机构名称:
¥ 1.0
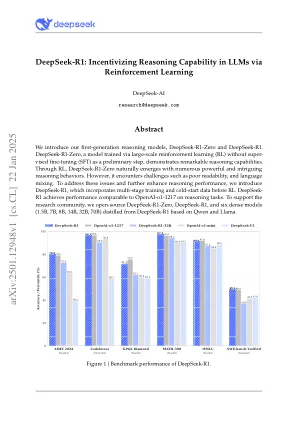
•分数:MMLU的90.8%,MMLU-PRO的84.0%,GPQA钻石的71.5%。•胜过DeepSeek-v3,但尾随OpenAI-O1-1217。•与其他封闭式模型相比,教育任务擅长于教育任务。SimpleQA:胜过DeepSeek-V3,展示了强大的事实查询处理。
DeepSeek-R1:通过增强学习激励LLM中的推理能力
主要关键词





相关文件推荐