机构名称:
¥ 1.0
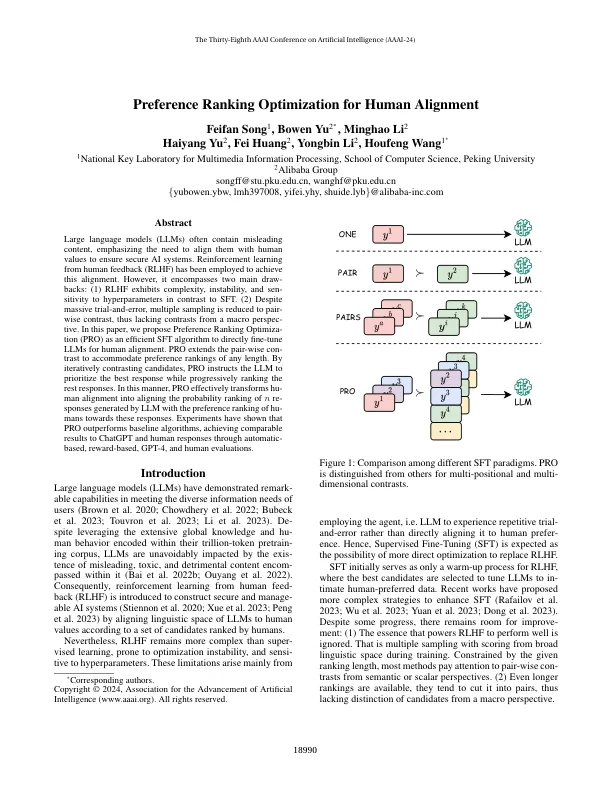
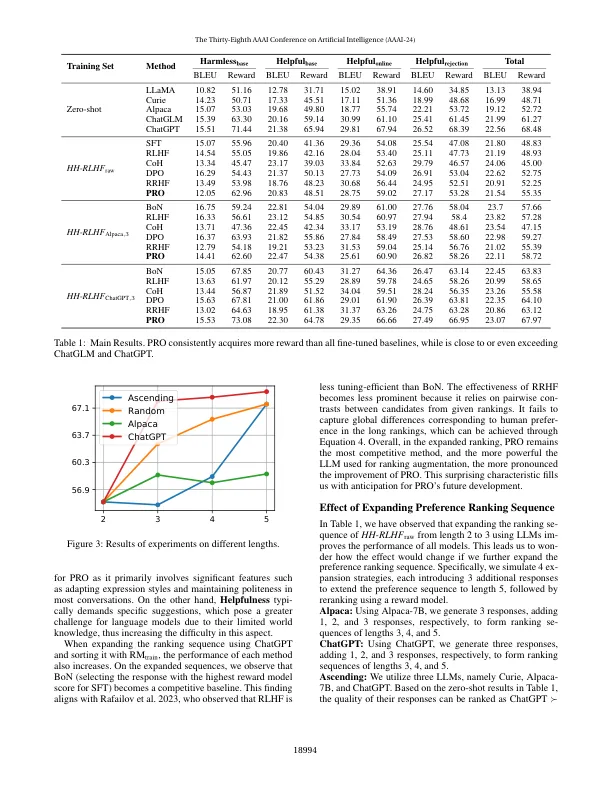
大型语言模型(LLMS)通常包含误导性内容,强调需要使它们与人类价值观保持一致以确保安全的AI系统。从人类反馈(RLHF)中学习的强化已被用来实现这一路线。然而,它包括两个主要的抽签:(1)RLHF表现出与SFT相反的对超参数的复杂性,不稳定和对超参数的现象。(2)尽管进行了大规模的反复试验,但多次抽样却降低为配对的对比度,因此缺乏宏观角度的对比度。在本文中,我们提出优先排名优化(PRO)作为有效的SFT算法,以直接对人类对齐进行微调。pro扩展了逐对的骗局,以适应任何长度的偏好排名。通过迭代对比候选人,Pro指示LLM优先考虑最佳响应,同时逐步对其余响应进行排名。以这种方式,Pro有效地将Human对齐方式转换为LLM产生的N重点的概率排名与Humans对这些响应的偏好排名。实验表明,Pro的表现优于基线算法,通过基于自动的,基于奖励的GPT-4和人类评估,与CHATGPT和人类反应取得了可比的结果。
偏好对人对齐的优化优化
主要关键词



相关文件推荐