
机构名称:
¥ 1.0
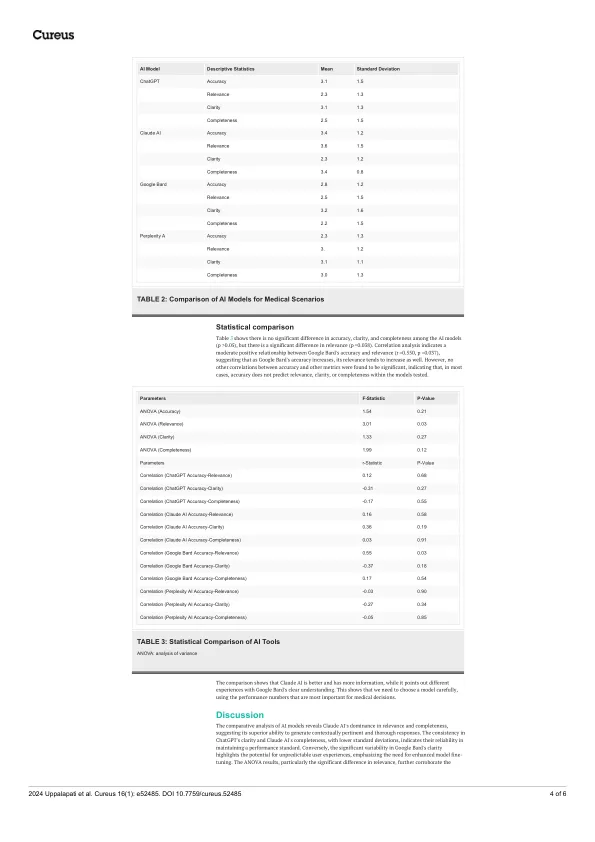
这项研究严格评估了四种人工智能 (AI) 语言模型(ChatGPT、Claude AI、Google Bard 和 Perplexity AI)在四个关键指标上的表现:准确性、相关性、清晰度和完整性。我们使用了多种研究方法,从 14 种场景中获取意见。这有助于我们确保我们的研究结果准确可靠。研究表明,Claude AI 的表现优于其他模型,因为它给出了完整的答案。与其他 AI 工具相比,其相关性平均得分为 3.64,完整性平均得分为 3.43。ChatGPT 一直表现良好,而 Google Bard 的回答不明确,差异很大,难以理解,因此 Google Bard 没有一致性。这些结果提供了有关 AI 语言模型在医疗建议方面表现良好或不佳的重要信息。它们帮助我们更好地使用它们,告诉我们如何改进未来使用 AI 的技术变革。研究表明,AI 能力与复杂的医疗场景相匹配。
评估 ChatGPT、Claude AI、Bard 和
主要关键词



相关文件推荐





























