
机构名称:
¥ 1.0
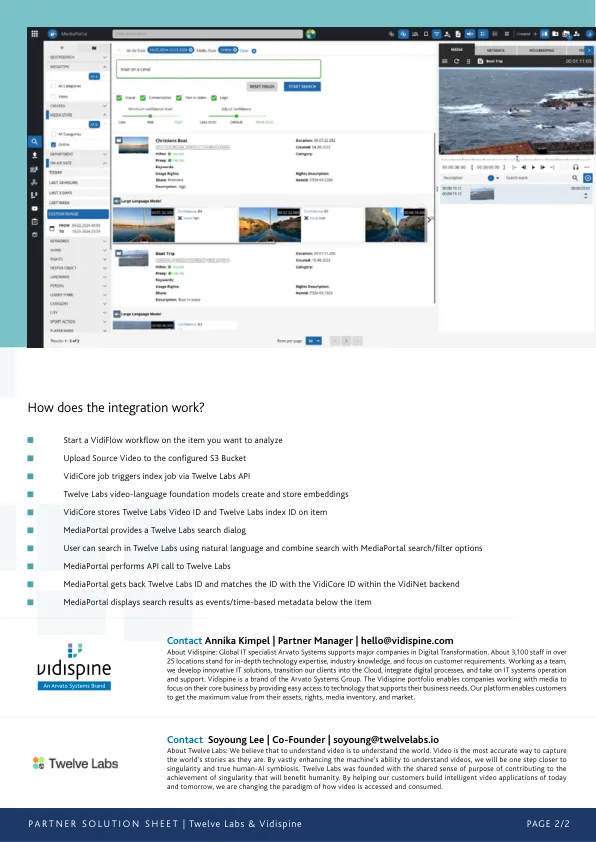
Twelve Labs 使用多模态视频语言基础模型来捕获视频的完整语义和上下文内容——这意味着捕获的语义和上下文内容存储在称为“嵌入”的矢量表示中,然后实现对视频的人类层面的理解。媒体服务平台 VidiNet 和 Twelve Labs 产品的集成提供了一种解决方案,使手动记录和元数据生成变得过时。将 Twelve Labs 的视频语言基础模型集成到直观的用户界面 MediaPortal 中,改变了用户搜索资料的方式,因为它无需在核心服务 Vidi-Core 中索引所有静态元数据字段。用户现在可以使用自然语言查询精确定位视频档案中的特定时刻,并与 VidiNet 索引的元数据无缝合并。但这到底意味着什么呢?用户现在可以使用自然语言查询在他们的视频中找到确切的时刻,并将它们与来自 Vidispine 应用程序的元数据相结合。
将视频理解 AI 提升到新水平
主要关键词

相关文件推荐


























