机构名称:
¥ 2.0
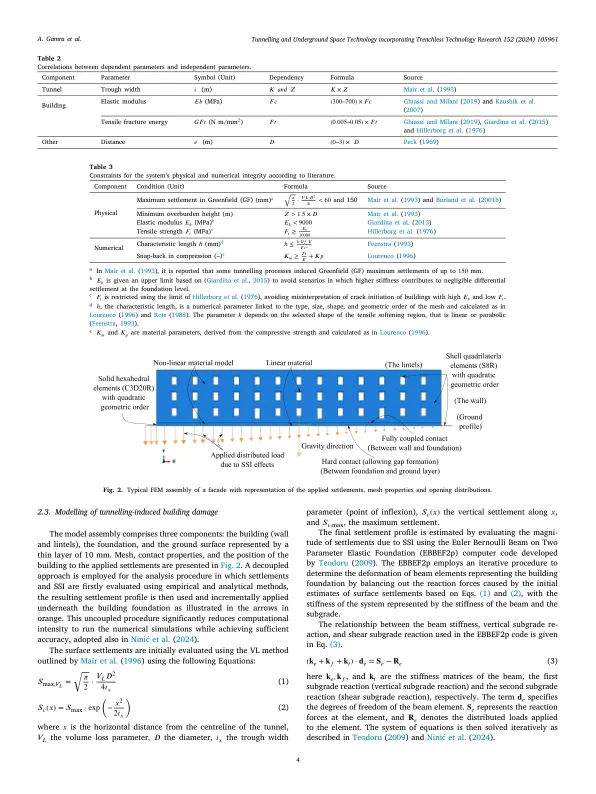
隧道施工引起的建筑物损坏评估是一个复杂的土壤-结构相互作用 (SSI) 问题,受土壤和结构的众多几何和材料参数的影响,具有强烈的非线性行为特征。目前,人们倾向于使用机器学习 (ML) 开发数据驱动模型来捕捉这种复杂行为。鉴于真实数据(通常来自特定案例研究)的稀缺性,许多研究人员已转向通过复杂且经过验证的数值模型(如有限元法 (FEM))创建大量合成数据集。然而,这些数据集的开发和高级 ML 算法的训练带来了重大挑战。带来了重大挑战。仅依赖案例研究得出的参数域和范围可能会导致数据分布不平衡,从而导致模型在人口较少的地区表现不佳。在本文中,我们介绍了一种通过迭代过程设计最佳高置信度数据集的策略。这个过程从系统的文献综述开始,以确定参数、它们的范围和依赖关系对 SSI 引起的建筑物损坏的重要性。从数百次 FEM 模拟开始,我们生成初始数据集,并通过敏感性分析 (SA) 研究、统计建模和在统计显著区域重新采样来评估其质量和影响。通过这种评估,我们可以改进模型的输入空间,寻找缓解输出分布不平衡的方案。重复该过程,直到数据集达到训练元模型的令人满意的平衡,从而有效地最大限度地减少偏差。我们的研究结果突出了这种方法在确定最佳和可行输入空间方面的成功,从而显著减少了输出特征的不平衡分布。这种方法不仅在我们的研究中被证明是有效的,而且还提供了一种通用的方法,可以适用于旨在生成高质量合成数据集的其他学科。
基于隧道施工对建筑物损坏的预测 - Pure
主要关键词




相关文件推荐