
机构名称:
¥ 1.0
并查集解码器是一种领先的算法方法,用于纠正表面代码中的量子误差,实现的代码阈值与最小权重完美匹配 (MWPM) 相当,且摊销计算时间与物理量子比特数近乎线性相关。这种复杂性是通过不相交集数据结构提供的优化实现的。然而,我们证明,由于双重分析和算法原因,解码器在大规模上的行为未充分利用此数据结构,并且可以对架构设计进行改进和简化以减少实践中的资源开销。为了加强这一点,我们模拟了解码器形成的擦除簇的行为,并表明在任何操作模式下,数据结构内都不存在渗透阈值。这为解码器在大规模上产生了线性时间最坏情况复杂度,即使使用忽略流行优化的简单实现也是如此。
不使用并查集的并查集量子解码
主要关键词




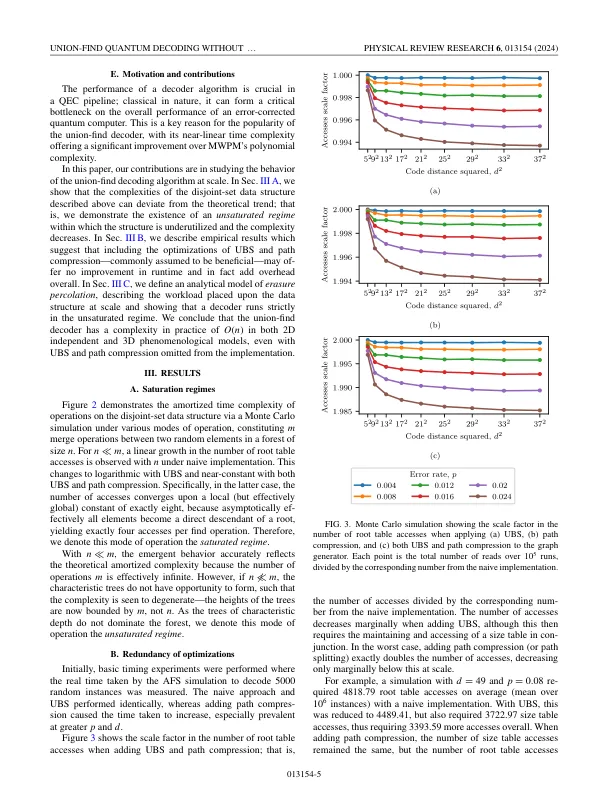
相关文件推荐





























