机构名称:
¥ 1.0
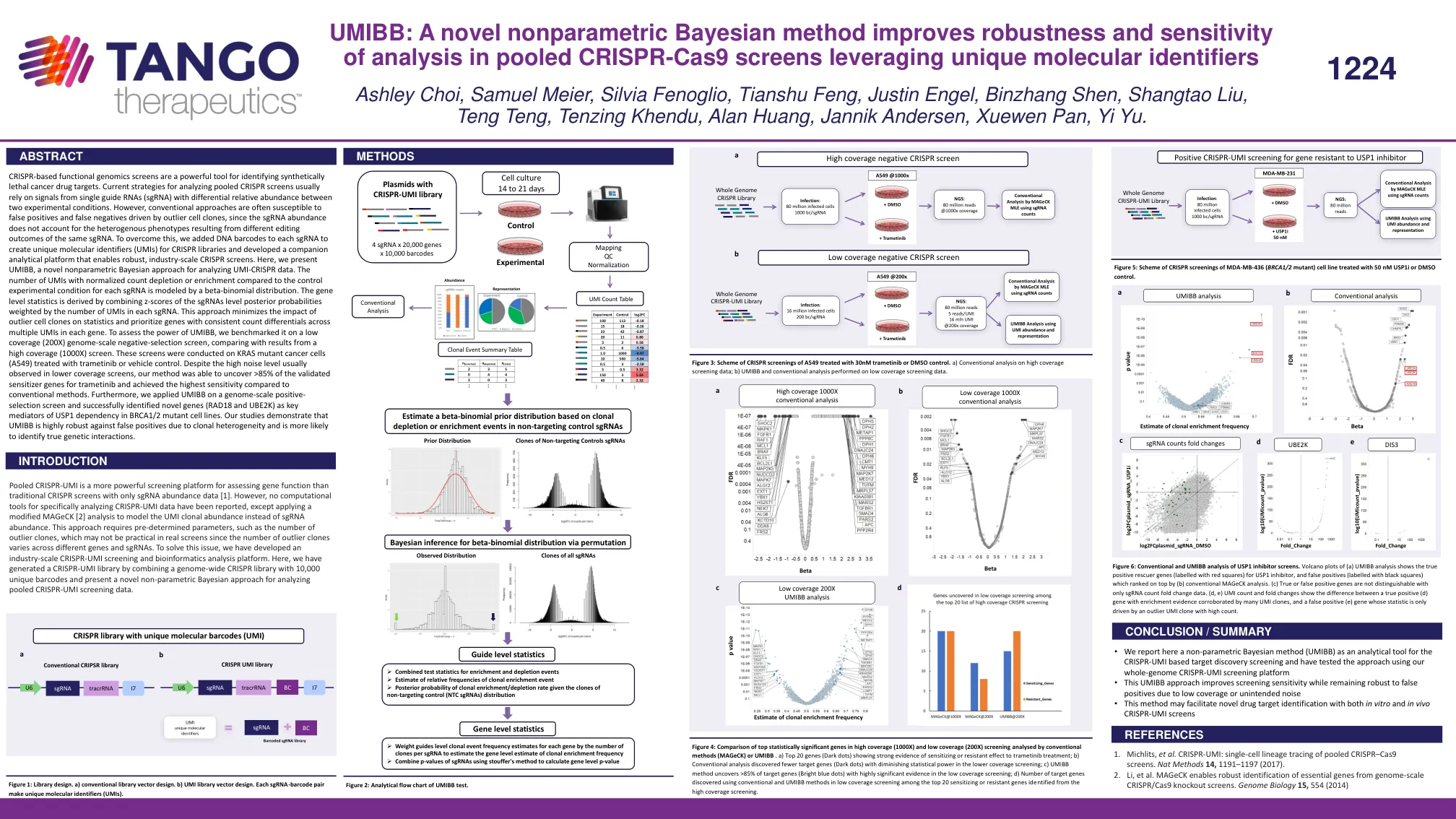
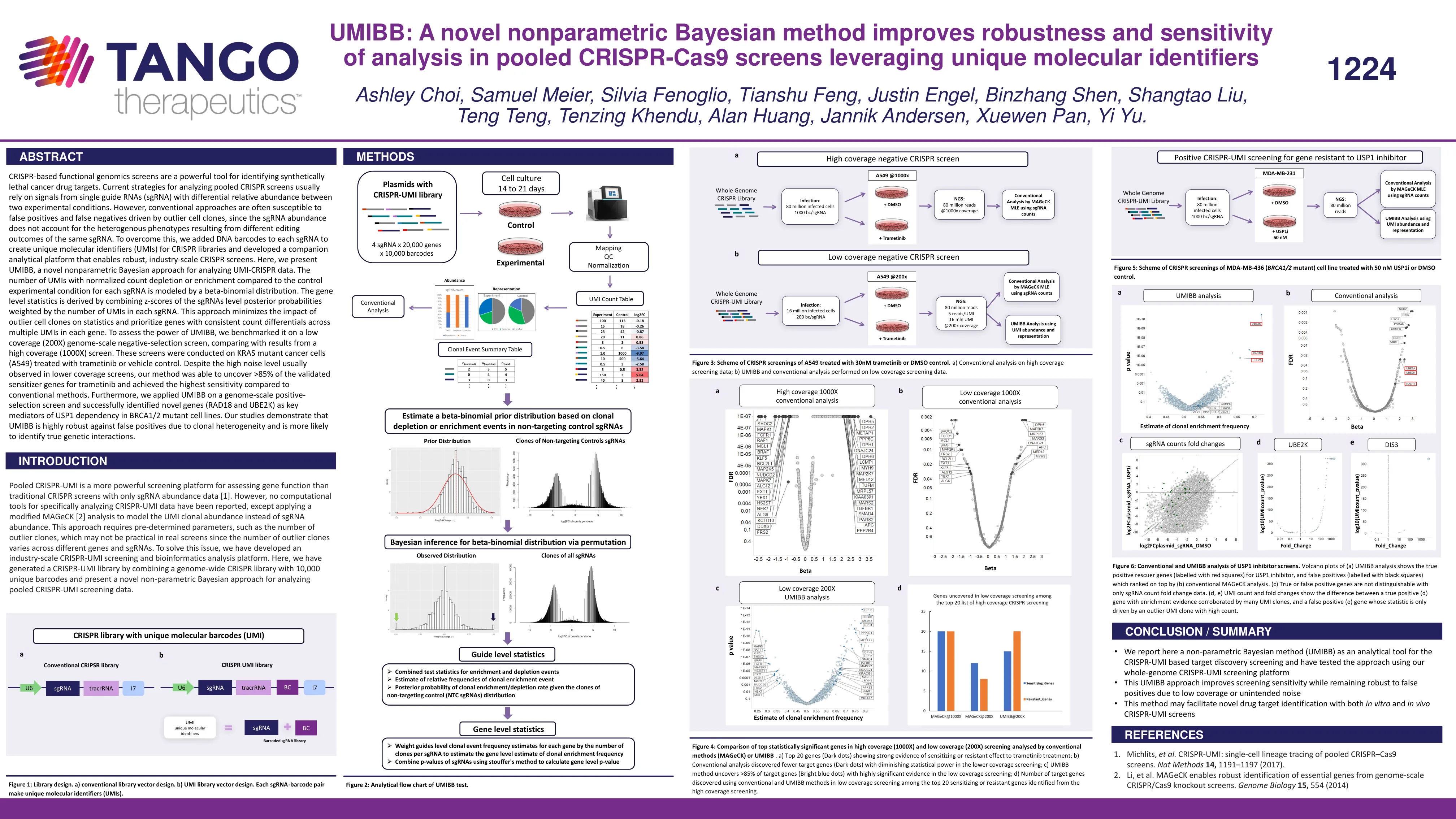
基于 CRISPR 的功能基因组学筛选是识别合成致死癌症药物靶点的有力工具。目前分析汇集的 CRISPR 筛选的策略通常依赖于来自在两种实验条件下具有不同相对丰度的单个向导 RNA (sgRNA) 的信号。然而,传统方法通常容易受到由异常细胞克隆驱动的假阳性和假阴性的影响,因为 sgRNA 丰度不能解释由相同 sgRNA 的不同编辑结果导致的异质表型。为了克服这个问题,我们在每个 sgRNA 中添加了 DNA 条形码,以创建 CRISPR 文库的唯一分子标识符 (UMI),并开发了一个配套的分析平台,以实现强大的工业规模 CRISPR 筛选。在这里,我们介绍了 UMIBB,一种用于分析 UMI-CRISPR 数据的新型非参数贝叶斯方法。与每个 sgRNA 的对照实验条件相比,具有标准化计数消耗或富集的 UMI 数量由 beta-二项分布建模。基因水平统计数据是通过将 sgRNA 水平后验概率的 z 分数与每个 sgRNA 中 UMI 的数量加权而得出的。这种方法最大限度地减少了异常细胞克隆对统计数据的影响,并优先考虑每个基因中多个 UMI 之间计数差异一致的基因。为了评估 UMIBB 的功效,我们在低覆盖率(200X)基因组规模负选择筛选上对其进行了基准测试,并与高覆盖率(1000X)筛选的结果进行了比较。这些筛选是在用曲美替尼或载体对照处理的 KRAS 突变癌细胞(A549)上进行的。尽管在较低覆盖率筛选中通常会观察到高噪音水平,但我们的方法能够发现 >85% 的曲美替尼已验证的致敏基因,并且与传统方法相比实现了最高的灵敏度。此外,我们将 UMIBB 应用于基因组规模的正向选择筛选,并成功确定了新基因(RAD18 和 UBE2K)是 BRCA1/2 突变细胞系中 USP1 依赖性的关键介质。我们的研究表明,UMIBB 对克隆异质性导致的假阳性具有很高的稳健性,并且更有可能识别真正的遗传相互作用。
UMIBB:一种新的非参数贝叶斯方法提高了稳健性和灵敏度
主要关键词
相关文件推荐


























