机构名称:
¥ 1.0
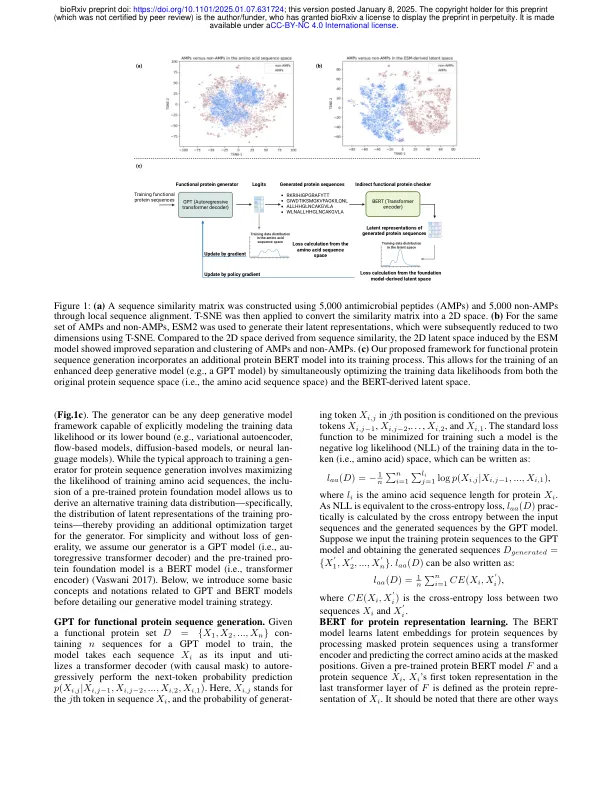
已经采用了各种深层生成模型来进行从头功能蛋白的产生。与3D蛋白设计相比,基于序列的生成方法旨在产生具有所需功能的氨基酸序列,由于蛋白质序列数据的丰度和质量以及相对较低的建模复合物,用于训练的氨基酸序列仍然是一种主要方法。通常对这些模型进行培训以匹配训练数据中的蛋白质序列,但每个氨基酸的精确匹配并不总是必不可少的。某些氨基酸的变化(例如,不匹配,插入和删除)可能不一定会导致功能变化。这表明将训练数据的可能性最大化超出氨基酸序列空间,可以产生更好的生成模型。预训练的蛋白质大语言模型(PLM)(例如ESM2)可以将蛋白质序列编码为潜在空间,并可能用作功能验证器。,我们通过模拟优化氨基酸序列空间和源自PLM的潜在空间的可能性,提出了训练功能蛋白序列生成模型。此培训方案也可以看作是一种知识蒸馏方法,该方法在培训过程中动态重新体重样本。我们将方法应用于训练GPT类模型(即自回旋变压器)进行抗微肽(AMP)和苹果酸脱氢酶(MDH)的一代任务。计算实验证实,我们的方法优于各种深层生成模型(例如,没有提出的培训策略的没有提议的培训策略)的各种深层生成模型(例如,生成对抗性净,变异自动编码器和GPT模型),证明了我们多叶型精选策略的有效性。
通过基础模型的潜在空间可能性优化改善功能蛋白的产生
主要关键词




相关文件推荐