
机构名称:
¥ 1.0
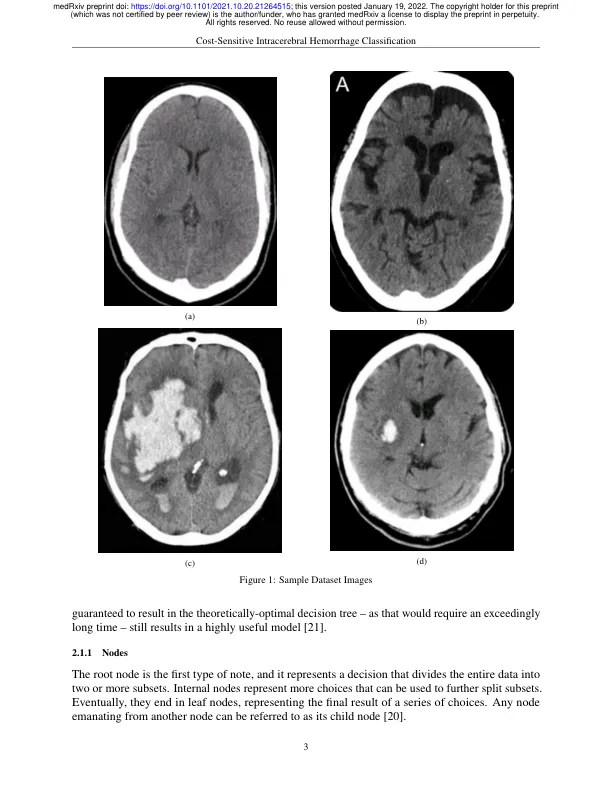
一位训练有素的放射科医生确认了这些图像的真实性,并没有发现任何标记错误的图像。因此,没有丢弃任何图像。为了在现实临床场景中最准确地反映模型的性能,图像没有以任何方式增强。随后创建了两个数据集:一个包含 160 幅图像的训练数据集和一个包含 40 幅图像的测试数据集。两个数据集中的出血性和非出血性 CT 扫描数量相等。值得注意的是,该数据集包含从万维网上搜索中获取的图像,因此由于源机器、患者状况、扫描时间、辐射剂量等的差异而引入了高度的异质性。这个问题因数据集较小而变得更加严重,因此这里获得的结果可能只是对所采用技术的实际潜力的保守估计 [17,18]。
通过成本敏感的机器学习在计算机断层扫描中检测脑出血
主要关键词




相关文件推荐





























