
机构名称:
¥ 1.0
摘要:背景:分析在多序列比对中等效位置上发现的氨基酸类型分布已应用于人类遗传学、蛋白质工程、药物设计、蛋白质结构预测和许多其他领域。这些分析往往围绕在进化等效位置上发现的二十种氨基酸类型的分布测量:多序列比对中的列。常用的测量方法是变异性、平均疏水性或香农熵。其中一种称为熵-变异性分析的技术,顾名思义,将一列中观察到的残基类型的分布简化为两个数字:香农熵和由观察到的残基类型数量定义的变异性。结果:我们应用了一种深度学习、无监督特征提取方法来分析所有人类蛋白质的多序列比对。对 27,835 个人类蛋白质多序列比对训练了自动编码器神经架构,以获得最能描述七百万种变异模式的两个特征。这两个无监督学习的特征与熵和变异性非常相似,表明这些是在降低多序列比对中列中隐藏信息的维数时保留最多信息的投影。
熵和变异性:深度学习的第二种观点
主要关键词



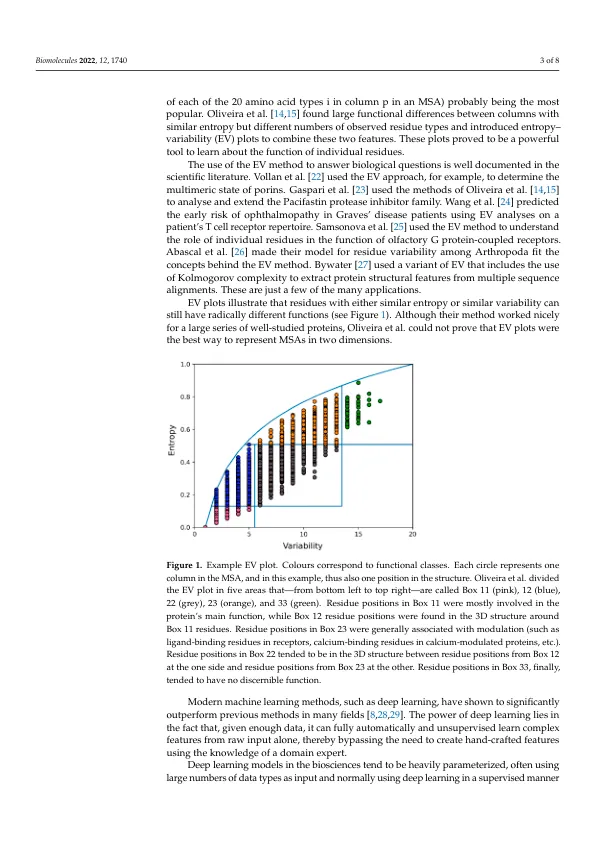

相关文件推荐





























