机构名称:
¥ 2.0
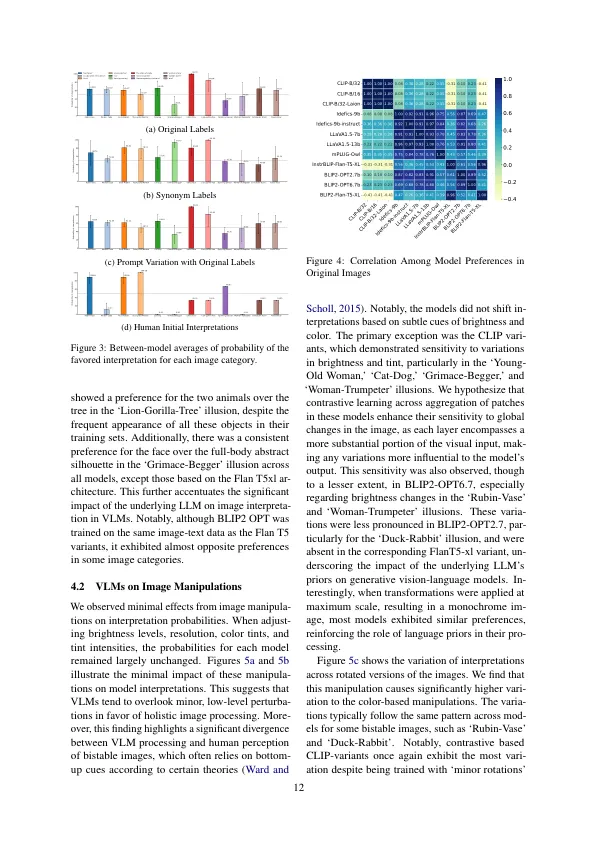
Bistable图像,也称为模棱两可的图像或可逆图像,显示了视觉刺激,尽管观察者并非同时,但可以在两个不同的解释中看到。在这项研究中,我们使用可动的图像对视觉模型进行了最广泛的检查。我们手动收集了一个数据集,其中包括29张Bissable图像以及它们的相关标签,并在亮度,色彩,旋转和分辨率方面进行了121种不同的操作。我们评估了六个模型体系结构的分类和属性任务中的十二个不同模型。我们的发现表明,除了来自Idefics家族和llava1.5-13b的模型外,在模型之间,一个相对于另一个相对于另一个相对于另一个相对于图像操作的差异的明显偏爱,对图像旋转的例外很少。另外,我们将模型的偏好与人类进行了比较,并指出这些模型并没有与人类相同的连续性偏见,并且通常与人类初始解释有所不同。我们还调查了提示中的变化和使用同义标签的影响,发现与图像训练数据相比,这些因素明显更多的是模型的解释,而不是图像较高的图像表现出对Bissable图像解释的影响更高。所有代码和数据都是开源的1。
评估双向图像上的视觉模型
主要关键词




相关文件推荐