
机构名称:
¥ 1.0
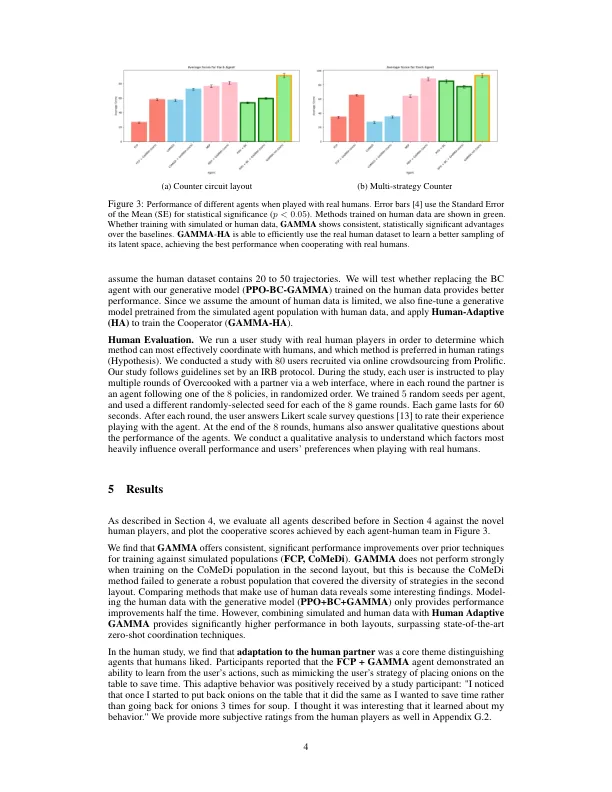
可以与人类协调零拍摄的培训代理是多代理增强学习(MARL)的关键任务。当前的算法专注于培训模拟的人类合作伙伴政策,然后将其用于培训合作者。模拟人类是通过克隆在人类数据集上的行为而产生的,或者通过使用MARL来创建模拟药物群体。但是,这些方法通常很难产生有效的合作者,因为所学的人类未能涵盖现实世界中人们采用的各种策略。我们表明,学习人类伴侣的生成模型可以有效地解决这个问题。我们的模型学习了人类的潜在变量表示,可以被视为编码人类的独特策略,意图,经验或风格。可以从任何(人类或神经政策)代理商相互作用数据,在先前工作中提出的统一方法灵活训练此生成模型。通过从潜在空间进行抽样,我们可以使用生成模型来生产不同的合作伙伴来训练合作者。我们评估了我们的方法 - 在熟练的情况下(伽马)的精力充沛,这是一种充满挑战的合作烹饪游戏,已成为零击协调的标准基准。我们对真正的人类队友进行了评估,结果表明,无论是在模拟人群还是人类数据集上训练生成模型,伽玛都会始终提高性能。1此外,我们提出了一种从生成模型中进行后验采样的方法,该方法偏向人类数据,使我们仅使用少量昂贵的人类交互数据有效地提高了性能。
学习使用生成剂与人合作
主要关键词




相关文件推荐





























