机构名称:
¥ 1.0
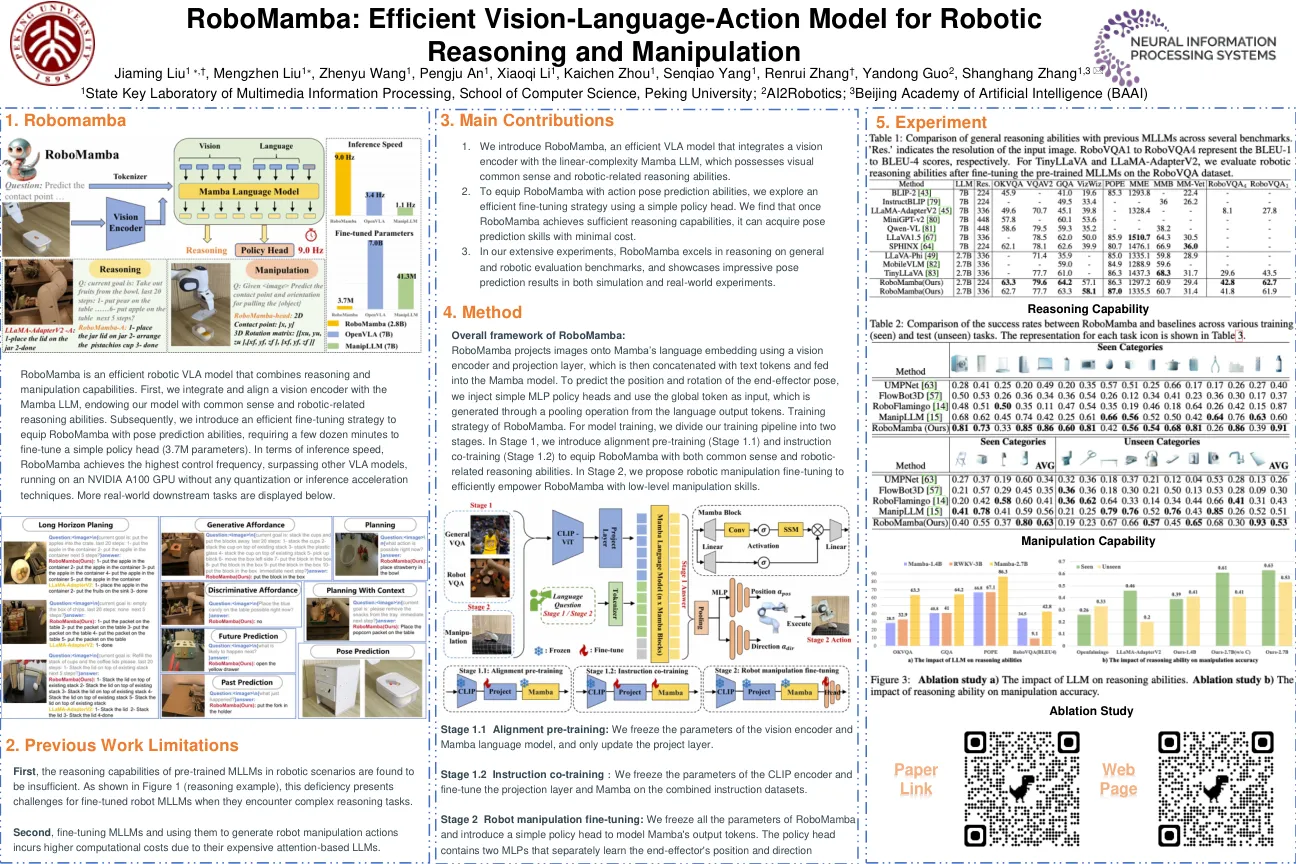
奖励工程长期以来一直是加强学习(RL)研究的挑战,因为它通常需要大量的人类努力和试验和错误的局限性来设计有效的奖励功能。在本文中,我们提出了rl-vlm-f,这种方法通过利用视觉语言基础模型(VLMS)来利用馈送供给,从而自动为代理人学习新任务的奖励功能,并仅对任务目标的文本描述和代理人的视觉观察来生成新任务。我们方法的关键是要查询这些模型,以根据任务目标的文本描述对代理的图像观察对偏好,然后从偏好标签中学习重新函数,而不是直接提示这些模型输出原始奖励分数,这可能是嘈杂和一致的。我们证明,RL-VLM-F成功地产生了各个领域的有效奖励和政策,包括经典控制,以及操纵刚性,清晰和可变形物体的操纵,而无需人工监督,不需要人类的先验方法,这些方法均超过了在同一假设下使用奖励生成的大型奖励模型。
RL-VLM-F:从视觉语言基础模型反馈
主要关键词





相关文件推荐