
机构名称:
¥ 1.0
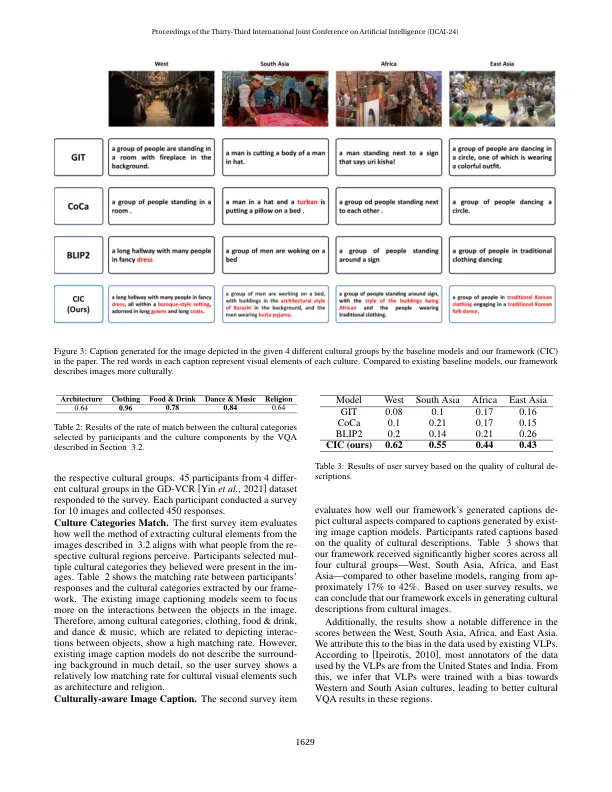
图像字幕使用视觉语言预先训练的模型(VLP)(例如Blip)从图像中生成描述性句子,该模型已得到很大改善。然而,当前的方法缺乏图像中描述的文化元素的详细描述标题,例如亚洲文化群体的人们穿着的传统服装。在本文中,我们提出了一个新的框架,具有文化意识的图像字幕(CIC),该框架生成字幕并描述从代表文化的图像中的文化视觉元素中提取的文化元素。受到通过适当提示来构建视觉模式和大语言模型(LLM)的方法的启发,我们的框架(1)基于图像中的文化类别产生问题,(2)提取文化的视觉问题(VQA)中的文化vi sual元素(VQA),并使用生成的问题以及(3)具有文化文化 - 瓦拉避难所使用llms的文化范围。我们对来自4个不同文化群体的45名参与者进行的人类评估对相应的文化有很高的了解,这表明,与基于VLP的图像字幕基线相比,我们提出的框架会产生更文化的描述性标题。可以在https://shane3606.github上找到。io/cic。
CIC:文化意识的图像字幕的框架
主要关键词




相关文件推荐




























