
机构名称:
¥ 1.0
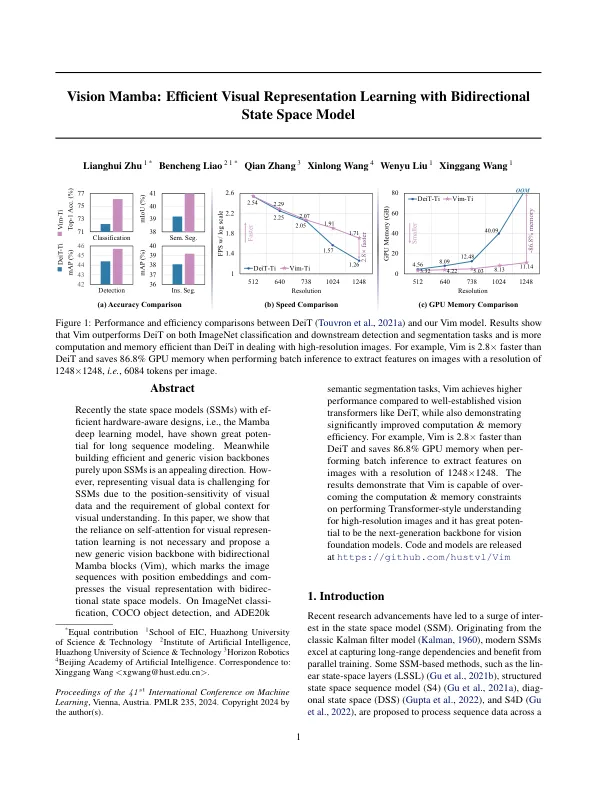
最近,具有效率的硬件感知设计的状态空间模型(SSM),即Mamba深度学习模型,已显示出长序列建模的巨大计算。同时,纯粹在SSM上建立有效和通用的视力骨干是一个吸引人的方向。,由于视觉数据的位置敏感性以及全球上下文对视觉理解的要求,代表视觉数据对SSM的挑战。在本文中,我们表明,对自我注意力的依赖无需进行视觉代表学习,并提出了带有双向Mamba块(VIM)的新的通用视觉主链,该主块(VIM)标记了带有位置嵌入的图像序列,并用Bidirectiact态态空间模型将视觉表示。Imagenet分类,可可对象检测和ADE20K
视觉mamba:双向状态空间模型的有效视觉表示学习
主要关键词




相关文件推荐




























