
机构名称:
¥ 3.0
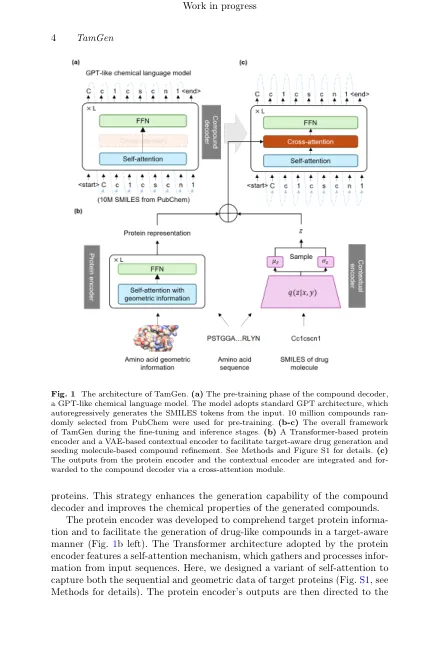
生成性药物设计是药物发现的一种很有前途的方法,其目的是从头开始创建具有所需药理特性的新型分子/化合物,而不依赖于现有的模板或分子框架 [ 2 , 3 ]。传统的基于筛选的方法,例如高通量筛选、虚拟筛选和新兴的基于深度学习的筛选 [ 4-7 ],通常从包含 104 至 108 个分子的库中寻找候选药物 [ 8-10 ],而生成性药物设计能够探索广阔的化学空间,据估计其中包含超过 1060 种可行化合物 [ 11 ]。因此,它有可能识别尚未充分探索的化合物类别和现有库中不存在的新化合物。这对于没有命中化合物(药物设计的起点)的靶蛋白和对现有药物产生耐药性的靶蛋白尤其重要。生成建模技术极大地增强了药物设计能力。近年来,得益于自回归模型 [ 18 ]、生成对抗网络 (GAN) [ 19 ]、变分自编码器 (VAE) [ 20 ] 和扩散模型 [ 12 ] 等创造性人工智能技术,越来越多的方法被提出来根据目标蛋白的信息来指导类药物化合物的生成。这些方法通过探索以目标靶标为条件的化学空间,证明了利用深度学习进行基于靶标的生成药物设计的可行性。然而,通常缺少生物物理或生化分析的验证 [ 21 ],因为大多数生成的化合物缺乏类药物化合物令人满意的理化性质,例如合成可及性。换句话说,尽管现有的方法生成了大量新型化合物,但它们难以证明其能够提供有效的候选化合物,从而提高现实世界的药物发现效率。因此,我们提出了一种名为 TamGen(目标感知分子生成)的方法。 TamGen 具有类似 GPT 的化学语言模型,旨在生成类似药物的化合物,其灵感来自大型语言模型 [ 22 ] 的成功。生成式预训练 Transformer [ 23 ] (GPT) 是大型语言模型的支柱,它不仅能生成文本 [ 22 ],还能生成图像 [ 24 ] 和语音 [ 25 ],还能理解
使用化学语言模型进行药物设计的目标感知分子生成*
主要关键词




相关文件推荐





























