机构名称:
¥ 1.0
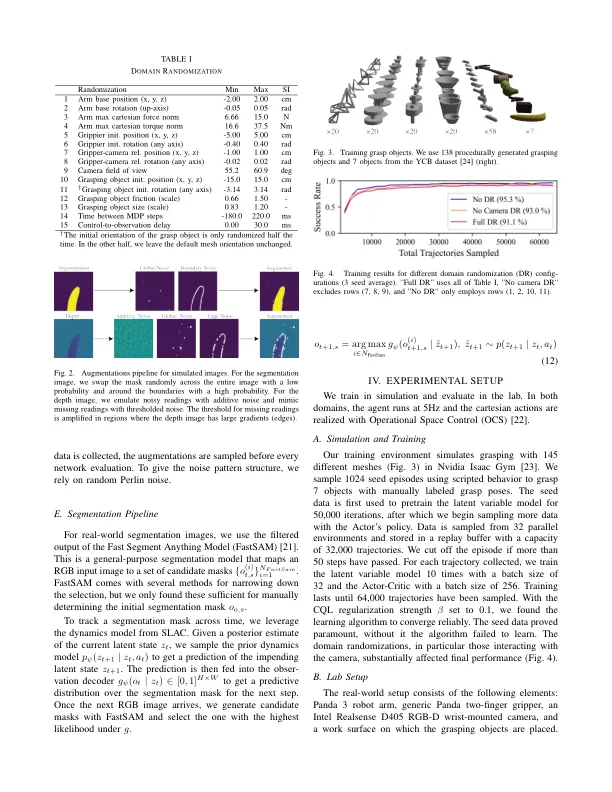
摘要 - 我们提出了一个基于深厚的增强学习(DRL)的基于新颖的6多型,6多的抓地框架,该框架能够直接合成笛卡尔空间中的连续6-DOF动作。我们所提出的方法使用了直觉的RGB-D摄像头的视觉观察,我们通过域随机化,图像增强和分割工具的结合来减轻SIM到真实的间隙。我们的方法包括一个非政策,最大渗透性,演员算法,该算法从二进制奖励和一些模拟示例grasps中学习了政策。它不需要任何现实世界的掌握示例,对模拟进行了完全训练,并且直接部署到现实世界中而没有任何微调。The efficacy o f o ur a pproach i s d emonstrated i n simulation and experimentally validated in the real world on 6-DoF grasping tasks, achieving state-of-the-art results of an 86% mean zero-shot success rate on previously unseen objects, an 85% mean zero-shot success rate on a class of previously unseen adversarial objects, and a 74.3% mean zero-shot success rate on a class of previously看不见,具有挑战性的“ 6-DOF”对象。可以在https://youtu.be/bwpf8imvook
6-DOF闭环抓握,并进行加固学习
主要关键词




相关文件推荐