机构名称:
¥ 3.0
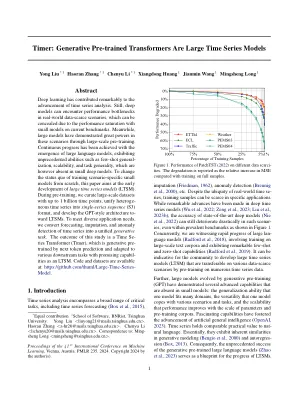
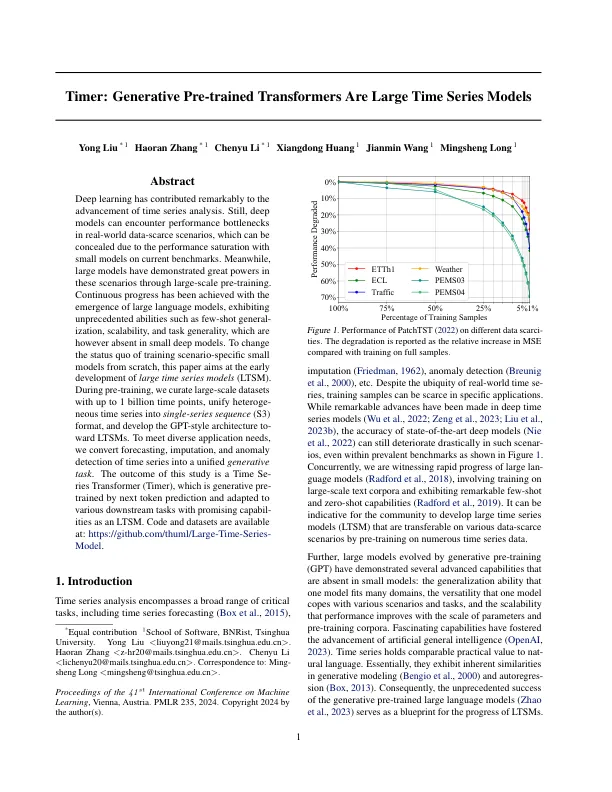
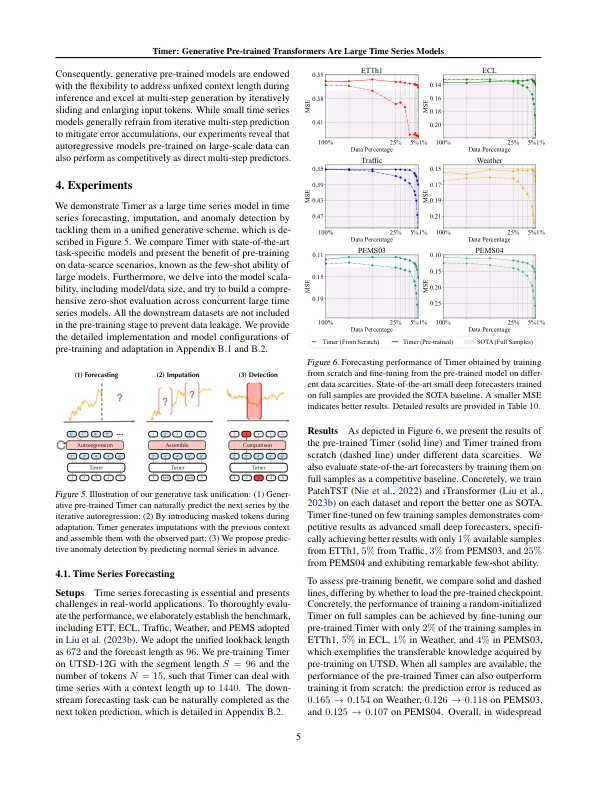
深度学习为时间序列分析的进步做出了显着贡献。仍然,深层模型可以在现实世界中数据筛选场景中遇到性能瓶颈,由于当前基准上的小型模型的性能饱和,可以隐藏它们。同时,大型模型通过大规模的预训练在这些情况下表现出了很大的力量。通过大型语言模型的出现,已经取得了持续的进步,这些模型表现出了前所未有的能力,例如少数通用,ization,可伸缩性和任务通用性,但是在小型深层模型中不存在。为了更改从头开始的训练方案特定小型模型的现状,本文旨在早期开发大型时间序列模型(LTSM)。在预训练期间,我们策划了最高10亿个时间点的大规模数据集,将杂项时间序列统一为单序列序列(S3)格式,并开发GPT型体系结构to-Ward ltsms。为了满足各种应用需求,我们将预测,归档和时间序列的异常检测转换为统一的生成任务。这项研究的结果是一个时间的变压器(计时器),它是由下一个令牌预测预测的生成性培训,并适用于具有有希望的Capabil-Ities作为LTSM的各种下游任务。代码和数据集可在以下网址提供:https://github.com/thuml/large time-series-模型。
计时器:生成预训练的变压器是大时间序列模型
主要关键词



相关文件推荐





























