
机构名称:
¥ 1.0
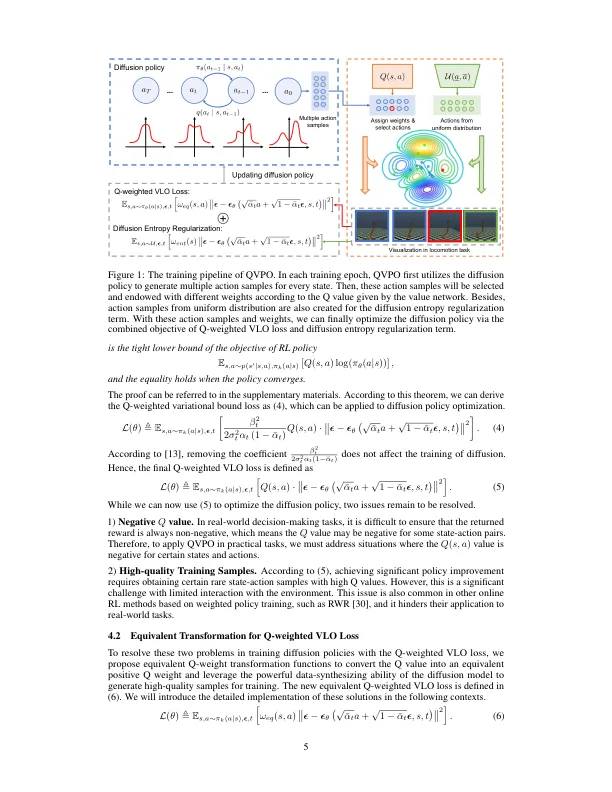
扩散模型在增强学习(RL)方面具有广泛的关注(RL),以表现出强大的表现力和多模式。已经证实,利用扩散策略可以通过克服非峰政策(例如高斯政策)的局限性来显着改善RL算法在连续控制任务中的性能。此外,扩散策略的多模式性还表明了为代理提供增强的勘探能力的潜力。但是,现有的作品主要集中于在离线RL中应用扩散政策,而将其纳入在线RL中的研究较少。由于“良好”样本(动作)不可用,因此无法直接应用于在线RL中的扩散模型的训练目标,称为变异下限。为了将扩散模型与在线RL协调,我们提出了一种基于无模型扩散的新型在线RL算法,称为Q-PRIATION策略优化(QVPO)。具体来说,我们在实践中介绍了Q加权变分损失及其近似实施。值得注意的是,这种损失被证明是政策目标的紧密下限。为了进一步增强扩散策略的勘探能力,我们设计了一个特殊的熵正规化项。与高斯政策不同,扩散政策中的对数可能是无法访问的。因此,此熵项是不平凡的。此外,为了减少扩散政策的巨大差异,我们还通过行动选择制定了有效的行为政策。这可以进一步提高在线交互期间的样本效率。因此,QVPO算法利用了扩散策略的探索能力和多模式,从而阻止了RL代理融合到亚最佳策略。为了验证QVPO的有效性,我们对Mujoco连续控制基准进行了综合实验。最终结果表明,QVPO在累积奖励和样本效率方面都可以达到最先进的表现。我们的官方实施在https://github.com/wadx2019/qvpo/中发布。
通过Q加权变化策略优化的基于扩散的增强学习
主要关键词




相关文件推荐





























