
机构名称:
¥ 1.0
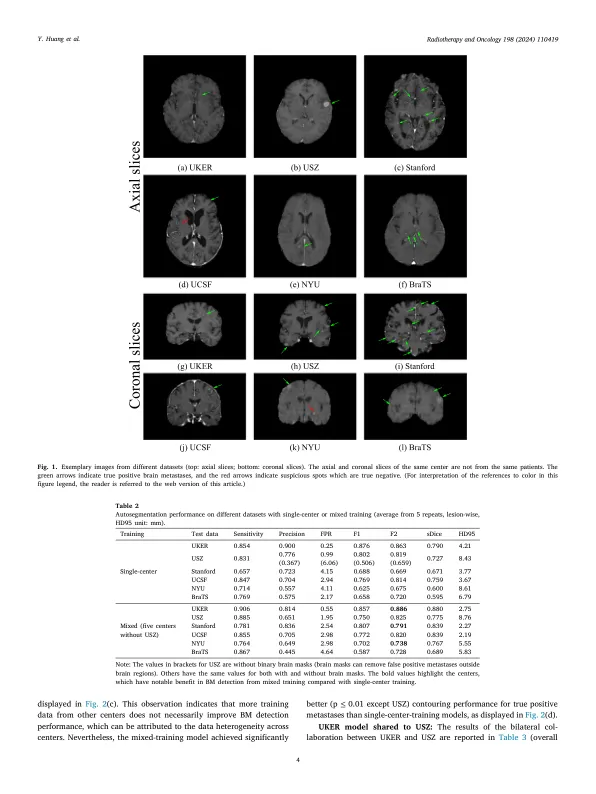
目标:这项工作旨在探索多中心数据异质性对深度学习脑转移(BM)自动分量性能的影响,并评估增量转移学习技术的功效,即不忘记(LWF),以提高模型性能而无需共享原始数据。材料和方法:使用了埃尔兰根大学医院(UKER),苏黎世大学医院(USZ),斯坦福大学,纽约大学(纽约大学)和Brats Challenge 2023的六个BM数据集。首先,分别为单一中心训练和混合多中心训练建立了用于BM自动分量的DeepMedic网络的性能。随后评估了保护隐私的双边合作,其中有一个验证的模型将分享到其他带有LWF或不带有LWF的转移学习(TL)的进一步培训中心。结果:对于单中心训练,在各自的单中心测试数据上,BM检测的平均F1得分范围从0.625(NYU)到0.876(UKER)。混合的多中心训练明显提高了斯坦福大学和纽约大学的F1分数,其他中心的改进可以忽略不计。当将UKER预告量化的模型应用于USZ时,LWF的平均F1得分(0.839)比NAIVE TL(0.570)和单中心训练(0.688)高于UKER和USZ测试数据。幼稚的TL提高了灵敏度和轮廓精度,但会损害精度。相反,LWF表现出值得称赞的灵敏度,精度和轮廓精度。应用于斯坦福大学时,观察到类似的性能。结论:数据异质性(例如,转移密度,空间分布和图像空间分辨率的变化)导致BM自动分量的性能变化,从而对构建概括性提出了挑战。LWF是对点对点隐私模型培训的有前途的方法。
多中心 - 私人 - 抛光模型 - 深度训练 -
主要关键词




相关文件推荐





























