
机构名称:
¥ 1.0
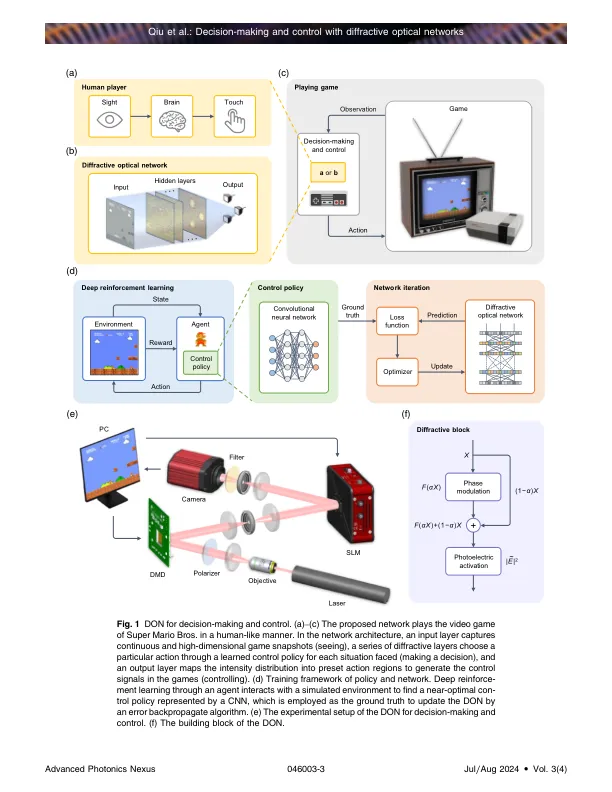
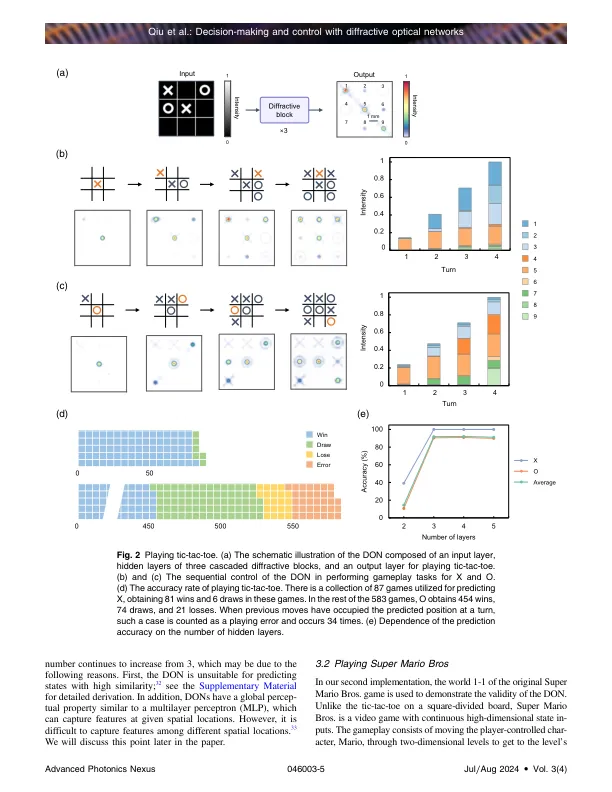
摘要。人工智能(AI)的最终目标是模仿人的大脑,直接从高维感觉输入中执行决策和控制。衍射光网(DONS)为实现高速和低功率消耗的AI提供了有希望的解决方案。大多数报告的DON专注于不涉及环境互动的任务,例如对象识别和图像分类。相比之下,尚未开发能够决策和控制的网络。在这里,我们建议使用深度强化学习来实施模仿人类级决策和控制能力的DON。这样的网络利用残差体系结构,可以通过与环境互动来找到最佳的控制策略,并且可以轻松地与现有的光学设备实现。使用三种类型的经典游戏来验证出色的性能:TIC-TAC-TOE,SUPER MARIO BROS。和RACENing。最后,我们提出了一个基于空间光调制器网络播放TIC-TAC-TOE的实验证明。我们的工作代表着前进的D型迈出的坚实一步,这有望从简单识别或分类任务转变为AI的高级感官能力的基本转变。它可能会在自动驾驶,智能机器人和智能制造中找到令人兴奋的应用程序。
衍射光网络的决策和控制
主要关键词



相关文件推荐





























