机构名称:
¥ 18.0
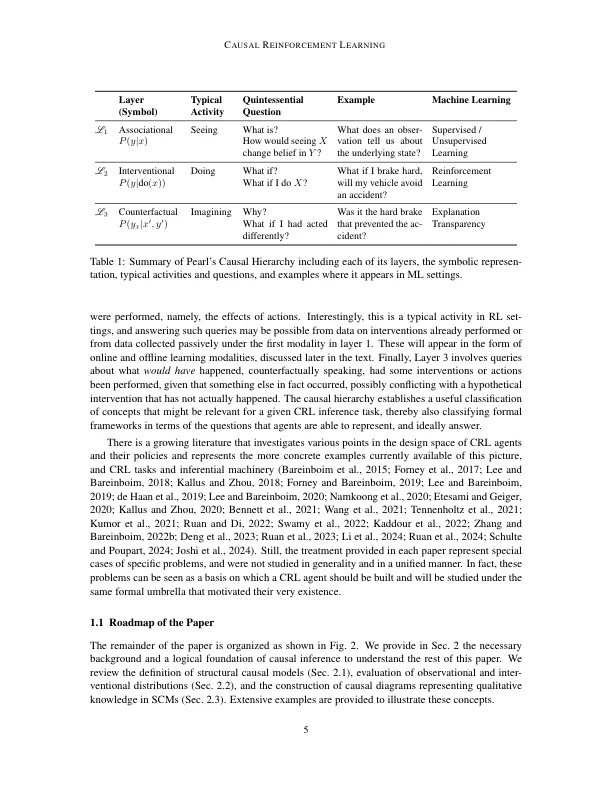
因果推论提供了一组原则和工具,使人们可以将数据和知识结合起来,以与反事实性质的问题相结合,即如果现实是不同的,即使目前没有这种未实现现实的数据,也会发生的事情。强化学习提供了一系列方法,以学习一项优化特定措施(例如,奖励,遗憾)的政策,当代理人部署在环境中并采用探索性,反复试验的方法时。这两个学科已经独立发展,并且几乎没有相互作用。我们注意到,它们在同一构件的不同方面(即反事实关系)运作,这使它们毫无双重地连接。基于这些观察结果,我们进一步意识到,当这种联系被明确承认,理解和数学时,自然会出现各种新颖的学习机会。为了意识到这一潜力,我们进一步指出,部署RL药物的任何环境都可以分解为一种自主机制的集合,这些机制导致不同的因果不变,并且可以将其作为结构性因果模型而拼凑而成;今天的任何标准RL设置都暗示着这些模型之一。反过来,这种自然形式化将使我们能够将不同的学习方式(包括在线,非政策和因果关系学习)置于统一的处理方式下,这些学习似乎在文献中似乎无关。关键字:结构性因果模型,干预措施,反事实,增强学习,识别能力,鲁棒性,非政策评估,模仿学习。有人可能推测,这三种标准学习方式是详尽的,因为所有可能的反事实关系都是通过连续实施来学习的。我们表明,通过引入几种自然而普遍的学习环境类别,这些设置不符合这些方式,而是需要新颖的维度和类型的分析。特别是,我们将通过因果镜头介绍和讨论,在线学习的问题,在哪里进行干预,模仿学习和反事实学习。这组新的任务和理解会导致更广泛的相反学习的看法,并提出了研究因果推断和并排学习的巨大潜力,我们称之为因果关系加强学习(CRL)。
因果增强概论学习
主要关键词




相关文件推荐