机构名称:
¥ 3.0
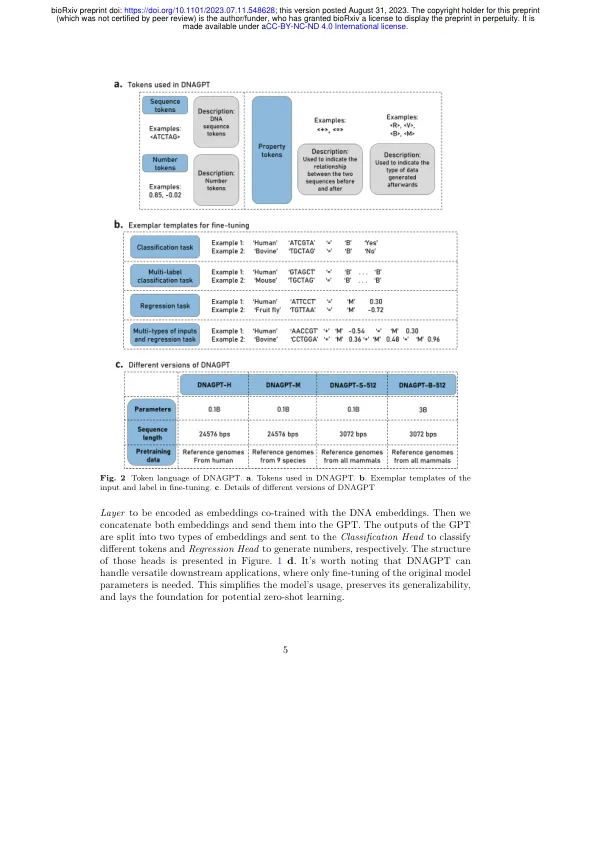
预先训练的大语言模型表明了从DNA序列中提取信息的潜力,但是适应各种任务和数据模式仍然是一个挑战。为了解决这个问题,我们提出了DNAGPT,这是一种对所有哺乳动物的超过2000亿碱基对训练的广义DNA预训练模型。通过使用二进制分类任务(DNA序列顺序)增强经典的GPT模型,一个数值回归任务(鸟嘌呤 - 环胞嘧啶内容预测)以及全面的令牌语言,DNAGPT可以处理多功能DNA分析任务,同时处理序列和数值数据。我们对基因组信号和区域识别,mRNA丰度回归和人工基因组生成任务的评估表明,与为特定的下游任务设计的现有模型相比,DNAGPT的表现优于卓越的性能,受益于使用新设计的模型结构的预培训。
dnagpt:用于多功能DNA序列分析任务的广义预训练工具
主要关键词




相关文件推荐